Comportement d'un programme
Examinons maintenant comment un programme utilise la mémoire de l'ordinateur pendant son exécution. Pour étudier ce comportement imaginons que celle-ci soit découpée en blocs physiques, appelés pages, de longueur fixe, tout comme un disque est découpé en secteurs. La taille de la page varie suivant les systèmes d'exploitation. Elle est de 512 octets dans la plupart des systèmes Unix, elle atteint 2048 octets dans les plus grosses machines.
L'adresse d'un mot de la mémoire peut être définie par la combinaison du numéro p de la page qui le contient et d'un déplacement d qui est son adresse relative dans la page. Soit S la taille de la page. On établit simplement la valeur a de l'adresse absolue au moyen de la relation : a = p.S + d.
Des études statistiques ont montré le comportement suivant :
- Au cours de la vie d'un processus, 75% des références concernent moins de 20% des pages. Cela signifie que les déplacements, les branchements se produisent dans un nombre réduit de pages.
- A un instant donné, les références observées sont le plus souvent locales. Cela signifie que la distance entre l'instruction courante et la suivante est petite. De même lorsqu'on manipule des variables elles se trouvent rangées à des adresses voisines. Lorsqu'un programme exécute une instruction dans une page de numéro pi il utilise pendant un temps ti relativement long un ensemble de pages voisines de celle-ci. Puis apparaît une période de transition très erratique avant que le processus ne recommence.
Ces constatations signifient que l'on charge, dans la mémoire d'un ordinateur, de nombreuses informations qui ne sont pas immédiatement indispensables au fonctionnement du processus.
Imaginons maintenant que nous disposions d'une mémoire physique plus petite que l'image virtuelle du programme. On ne peut charger qu'une partie du code du programme mais cela lui permet de démarrer. Le processus exécute alors un certain nombre d'instructions puis, à un certain point de son exécution, cherche à se brancher à l'adresse d'une instruction rangées dans une autre page qui n'est pas en mémoire. Il se produit alors un défaut de page.
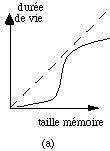
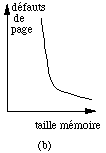
figure 5.11 : Durée de vie et nombre de défauts de page, en fonction de la taille de la mémoire
La figure 5.11 montre deux aspects du comportement statistique des programmes. Dans la figure a on a indiqué le temps qui s'écoule entre défauts de pages successifs, en fonction de la taille de la mémoire de l'ordinateur. Dans la figure b, on a indiqué le nombre de défauts de pages en fonction de ce même paramètre. Dans ces graphiques, la taille de la mémoire est normalisée en fonction de la taille moyenne des programmes qui sont exécutés. La durée de vie est l'intervalle de temps qui sépare deux défauts de page consécutifs. On remarque qu'au-delà d'une certaine valeur, il n'est plus rentable d'augmenter la taille de la mémoire car le nombre de défauts de pages ne diminue plus de façon sensible et cela n'améliore pas la durée de vie. Si l'on dispose d'un dispositif qui permet alors de charger les pages manquantes il devient possible d'employer une mémoire physique plus petite que la taille du code.
Le raisonnement a été fait en parlant d'instructions. Il peut être repris en ce qui concerne le segment de données. Un tableau pourrait ainsi être chargé morceau par morceau
Allocation statique de la mémoire
Imaginons une structure où la mémoire est partionnée tout comme un disque. La mémoire est allouée de façon statique, dans des partitions fixes déterminées dés le démarrage de l'ordinateur. Chaque programme est chargé dans une partition différente. Lors de la copie du module binaire depuis le disque vers la mémoire, toutes les adresses à employer sont obtenues en ajoutant à celle du code sur le disque celle du début de la partition (le code commence à l'adresse 0 dans le module compilé placé sur le disque).
Un défaut de page ne peut se produire puisque le programme est intégralement dans la mémoire. Dans le cas de systèmes multitâches, où plusieurs processus coexistent, l'ensemble de leurs codes doit être contenu dans l'ensemble des partitions alors que très peu de pages sont actives à un instant donné. L'ordinateur doit donc être équipé d'une très grande mémoire qui est très mal utilisée. On peut remédier à cet inconvénient en interrompant un programme puis en le déchargeant entièrement sur le disque pour réquisitionner l'espace qu'il occupait. Ce système manque de souplesse lorsque la taille des partitions n'est pas adaptée à la taille des codes que l'on veut exécuter. Il faut alors reconfigurer l'ordinateur, ce qui impose de l'arrêter. La protection entre processus est assez simple à réaliser puisqu'ils fonctionnent chacun dans des partitions séparées.
L'allocation statique de la mémoire n'est plus guère employée que dans des systèmes temps réel de commande de processus industriels où le nombre de programmes actifs simultanément est réduit. Un partitionement peut être prévu une fois pour toutes puisque ce sont toujours les mêmes programmes qu'on utilise. Ces ordinateurs sont optimisés pour réagir le plus rapidement possible aux sollicitations externes et la simplification de leur système d'exploitation apporte un gain dans leurs performances. Ils ont servis notamment pour construire des centraux téléphoniques.
Allocation dynamique de la mémoire
Dans les systèmes plus évolués la mémoire n'est pas partitionnée : on alloue les emplacements, dans la mémoire, en fonction de la taille des programmes à exécuter. Il faut prévoir des protections entre processus car ils fonctionnent tous dans le même espace virtuel et tout débordement intempestif de l'un d'eux risquerait de perturber le fonctionnement des autres. Cette allocation dynamique permet une grande souplesse de fonctionnement car plusieurs processus, de taille variable, peuvent coexister dans la mémoire physique et fonctionner simultanément. Il n'est plus nécessaire de prévoir à l'avance les caractéristiques des programmes à exécuter.
Un processus est constitué de plusieurs segments. Un segment ne peut être brisé et il est chargé sur une plage d'adresses contiguës, sinon le calcul des translations d'adresses nécessaire pour obtenir les adresses en mémoire à partir du programme compilé sur disque, deviendrait très compliqué. Certains systèmes exigent même que tous les segments d'un programme soient chargés simultanément. Pour permettre un fonctionnement efficace et minimiser les recherches d'adresses lors de l'exécution du processus, certains éléments fondamentaux comme les primitives les plus employées, les zones de sauvegarde du contexte ..., sont chargés à des adresses fixes, au début de la mémoire et alloués de façon statique.
Le chargeur qui gère la politique d'allocation de la mémoire, maintient une table des zones libres et obéit à l'une des politiques suivantes pour allouer celle-ci :
- politique du meilleur ajustement : il charge le segment dans la plage libre dont la taille correspond le mieux à sa longueur. Cette méthode n'est pas forcément très efficace. La zone choisie n'est pas rigoureusement égale à la taille du segment et il reste forcément un petit espace inoccupé. Rapidement la mémoire se trouve parsemée de petites zones libres inutilisables dont la somme peut devenir importante. Le problème est tout à fait analogue à celui des disques que nous évoquions au chapitre IV.
- politique du plus grand résidu : au contraire de la précédente, cette méthode cherche à placer un segment dans la plage libre la plus grande. Ceci laisse inoccupé de grands emplacements en espérant pouvoir les utiliser pour le chargement du prochain segment. Néanmoins la mémoire est également morcelée. Des études statistiques ont montré que ce n'était pas une bonne politique.
- La dernière méthode est tout simplement de choisir le premier emplacement libre qui convienne. Paradoxalement ce n'est pas une mauvaise solution. Les deux politiques précédentes sont coûteuses en temps de recherche et finalement peu efficaces, comme nous l'avons vu.
Dans tous les cas on aura du mal à éviter le morcellement. Tout comme on restructure un disque pour tasser ou défragmenter les fichiers, certains systèmes disposent de procédés de récupération de l'espace libre de la mémoire. La table de gestion des zones libres est régulièrement consultée et le système déclenche un processus de tassage ou swap lorsque des processus ne peuvent plus être chargés, alors qu'une quantité suffisante de mémoire libre existe mais est morcelée. Toute l'activité est interrompue, l'exécution des processus est arrêtée, ils sont recopiés sur le disque puis rechargés l'un après l'autre à partir du début de la mémoire. Il faut également remettre à jour leur contexte de fonctionnement. Ceci est analogue à ce que font, d'une manière plus simplifiée, les utilitaires de restructuration des disques que nous avons évoqué au chapitre précédent.
L'existence d'un dispositif de swap permet même d'envisager, qu'à un instant donné, la taille totale des processus en cours d'exécution soit supérieure à la taille de la mémoire physique. Chacun d'entre eux doit pouvoir tenir dans la mémoire physique et tous doivent coexister dans le fichier de swap. Les moins prioritaires y sont déchargés pendant leur période d'inactivité. Remarquons que pour pouvoir utiliser ce dispositif il est nécessaire de disposer sur le disque d'une image de la mémoire physique qui contienne tous les programmes en cours d'exécution. Ce fichier, appelé fichier de swap ou fichier d'échange, doit être suffisamment grand pour contenir à la fois les images des processus actifs et celles de ceux qui ont été déchargés car l'espace qu'ils occupaient a été réquisitionné. Il est intéressant de noter que si le module exécutable est organisé en segments séparés pour le code et les données, il suffit, lors de l'interruption, de recopier dans le fichier de swap, les segments de données puisqu'ils sont les seuls à être modifiés au cours de l'exécution du programme. Cette technique est employée sur les machines Cray. A un instant donné, un programme actif est soit entièrement en mémoire soit dans le fichier de swap. C'est également le cas de Windows. Le code de certains processus échappe à ce mécanisme et est fixé en mémoire pour sa durée de vie : il s'agit de processus qui contribuent aux fonctions fondamentales du système d'exploitation et pour lesquels le temps perdu dans le chargement/déchargement entre la mémoire et le fichier de swap serait trop pénalisant.
Que se passe-t-il lorsqu'un programme fait des allocations dynamiques de mémoire (fonction malloc())? Si le code de retour de la fonction n'est pas testé et si la mémoire disponible devient insuffisante, le programme se met en erreur puisque l'adresse en mémoire demandée n'existe pas. Ceci est bien connu de ceux qui emploient des programmes gourmands comme Photoshop lorsque la mémoire de leur ordinateur n'est pas très grande.
Mémoire paginée virtuelle
Principes généraux
Nous allons maintenant évoquer un fonctionnement plus complexe qui permet une grande souplesse dans le chargement des programmes. Il devient possible d'exécuter des processus dont la taille est très largement supérieure à celle de la mémoire physique.
L'image d'un programme, sur le disque, est constituée au moins de deux segments, l'un pour les instructions, l'autre pour les données, c'est à dire l'ensemble des variables scalaires, tableaux ou structures plus complexes définies dans le code. Chaque segment est lui-même constitué d'un ensemble de pages, comme nous les avons définies dans la section 5.2. Pour exécuter le processus on peut se contenter de charger un nombre limité de pages. Le chargeur (ou loader) utilise pour cela un dispositif de pagination qui établit la correspondance entre les adresses des pages dans le module exécutable sur le disque et celles des zones de la mémoire physique où ces pages sont chargées (fig. 5.12).
Dans ce dessin on a schématisé la façon dont deux pages d'un programme peuvent être chargées et adressées à travers cette fonction de pagination. Ce dispositif connaît, à tout instant, la liste des page libres dans la mémoire de façon à pouvoir en charger de nouvelles.
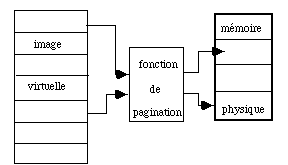
Figure 5.12 : Mécanisme d'adressage de la mémoire virtuelle
Soit M = 2m la taille d'une page, N = 2n le nombre de pages du programme et P = 2p la taille de la mémoire physique comptée en nombre de pages. La mémoire contient P cases où les pages peuvent être chargées. Une adresse, dans la mémoire, peut être construite en connaissant son numéro de case c et le déplacement dans cette case l. Une adresse, à l'intérieur du module exécutable, est construite à partir de la connaissance d'un numéro de page p et d'un déplacement d dans cette page (voir section 5.2). Les deux adresses, p et d, peuvent être rangées dans un mot en réservant un certain nombre de bits pour le numéro de page ou de case, le reste pour le déplacement d (fig. 5.13). Lors du chargement du module exécutable, la fonction de pagination permet, à partir de l'adresse de chargement du début du segment de décoder ces informations pour établir les correspondances d'adresse et en déduire l'adresse physique (c, l) correspondant à toute adresse virtuelle (p,d) à l'intérieur du segment.
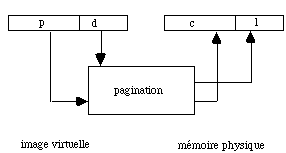
Figure 5.13 - Principe de codage des adresses
L'ensemble des codes des processus actifs est copié dans le fichier de swap ou swapfile. Celui-ci est la vraie mémoire de la machine car il contient l'image de l'ensemble des processus en cours d'exécution. Cette mémoire est paginée car constituée d'un ensemble de pages qui sont chargées séparément à la demande lorsqu'un défaut de page se produit et il n'est plus nécessaire qu'un programme soit contenu intégralement dans la mémoire. Cela suppose qu'il existe le dispositif de traduction des adresses que nous avons schématisé dans les figures 5.12 et 5.13. Le swapfile ou fichier de pagination contient tous les codes des programmes en cours d'exécution. Il est donc la mémoire virtuelle de l'ordinateur.
Unix fonctionne suivant ce principe. Comme la rapidité de ces échanges est cruciale pour l'efficacité du fonctionnement de la machine, ce fichier emploie des primitives d'accès spéciales et fonctionne dans une partition disque sééparée de structure spéciale optimisée pour ce fonctionnement.
Fonctionnement
Evoquons maintenant, plus en détails, le mécanisme de chargement et de déchargement d'un programme ainsi que sa pagination.
Comme les pages correspondant aux segments de données évoluent au cours de l'exécution elles doivent absolument être copiées dans le swapfile avant le chargement en mémoire. Par contre ceci n'est pas indispensable pour les segments de code, bien que cela soit fait dans la plupart des systèmes d'exploitation dont Unix : il est possible d'utiliser le segment code du module chargeable lui-même puisque les instructions ne sont pas modifiées durant l'exécution.
Au début de l'exécution un certain nombre de pages sont chargées dans la mémoire physique et le travail peut commencer. Lorsqu'une page de données doit être déchargée, elle est d'abord recopiée à son emplacement dans le swapfile. Lorsqu'un programme réclame une adresse dans une page qui n'est pas chargée, cela déclenche le mécanisme de pagination qui doit :
- trouver l'emplacement nécessaire pour charger la page manquante
- provoquer ce chargement
La fonction de pagination consulte la table des pages occupées dans la mémoire. Ce peut être une table à plusieurs niveaux d'indirection analogue à celle que nous avons décrite pour les fichiers dans la figure 4.20. Si elle trouve des emplacements libres, le chargement peut être déclenché. Le chargeur :
- calcule le numéro de page à charger à partir de l'adresse demandée par le processeur.
- charge la page manquante et indique que la zone de mémoire allouée est maintenant occupée.
Lorsqu'il n'existe plus de place libre dans la mémoire il faut supprimer certaines pages pour récupérer de l'espace. Le choix des pages à décharger est effectué en partant des considérations suivantes :
- il est moins onéreux de remplacer une page qui n'a pas été modifiée en mémoire car il est inutile de la recopier dans le fichier de pagination : elle y est déjà inscrite. Une page d'un segment de code est donc préférable à une page d'un segment de données qui aura certainement été modifiée depuis son chargement.
- une page allouée à un seul processus provoquera ultérieurement moins de défauts de page, si elle est enlevée, qu'une page partagée entre plusieurs.
- une page qui n'a pas été utilisée depuis longtemps a également moins de chance de provoquer un défaut. C'est pourquoi il faudrait inscrire la date exacte de dernière utilisation mais comme cela serait très onéreux en temps et en place, on se limite à mettre un bit à 1. Régulièrement un processus remet tous les bits de toutes les pages à zéro. Les pages dont le bit est levé ont donc été utilisées depuis le dernier passage et sont conservées si possible.
- Les processus d'allocation de page demandent beaucoup de ressources. On n'a donc pas intérêt à allouer les pages une à une. Il faut allouer à un processus, dés son démarrage, un espace raisonnable, puis par la suite charger des groupes de pages contiguës. Les politiques, sur ce point, dépendent de la réalisation du système d'exploitation. Elles ne sont pas les mêmes pour les différents systèmes qui existent sur le marché.
On comprend donc que la pagination est un mécanisme extrêmement coûteux en entrées-sorties. C'est pourquoi, dans les systèmes Unix, le fichier de swap n'est pas un fichier ordinaire. Il est construit séparément de tous les autres et accédé grâce à des fonctions spéciales qui court-circuitent celles utilisées pour les fichiers ordinaires. On cherche à obtenir le maximum de performances au moyen de fonctions spécialisées. Windows ne connaît pas cette subtilité. Le fichier de swap est un fichier ordinaire, ce qui explique en partie, le fonctionnement médiocre de la pagination.
Un exemple de fonctionnement est résumé dans la figure 5.14. Les programmes sont tout d'abord copiés dans le swapfile. Puis, au fur et à mesure des besoins des pages sont chargées ou déchargées. Le swapfile contient doit donc être assez grand pour contenir toutes les images des programmes actifs. L'expérience montre qu'il n'est pas raisonnable que sa taille soit supérieure, dans la plupart des cas, à trois fois la taille de la mémoire physique. On remarquera que le swapfile peut se trouver morcelé, tout comme dans le cas de l'allocation dynamique de la mémoire que nous avons évoqué dans la section 5.4. On utilisera des méthodes équivalentes pour le compacter.
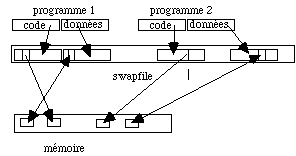
Figure 5.14 - Fonctionnement de la pagination
Limites d'un système à mémoire virtuelle paginée
Charger une page est onéreux. Cela consomme du temps du processeur, monopolise le bus et les dispositifs d'entrées-sorties. La probabilité d'un défaut de page augmente (fig. 5.11) lorsque la taille de la mémoire est petite. L'augmentation du nombre de processus simultanés, à taille de programme égale, a exactement le même effet puisque la mémoire disponible pour chacun d'entre eux diminue en raison inverse de leur nombre. Il faut donc choisir la dimension de la mémoire en fonction de la taille moyenne des programmes à exécuter simultanément et de leur nombre.
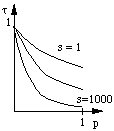 |
figure 5.15 : Taux d'utilisation
du processeur
|
Soit s = T/t le rapport du temps de chargement d'une page au temps moyen d'exécution d'une instruction. La figure 5.15 montre comment le taux moyen 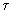 d'utilisation du processeur varie en fonction de ce rapport et de la probabilité p qu'un défaut de page se produise. p est déterminée par les caractéristiques des programmes qui s'exécutent et la taille de la mémoire. Pour une valeur donnée de p, ce graphique montre comment s'écroule lorsque s augmente. Ceci montre combien il serait catastrophique d'attacher à une machine rapide des disques à accès lent: T serait grand donc s également. Ceci doit être pris en compte, à l'heure actuelle, alors qu'on trouve sur le marché à un prix très raisonnable, des stations de travail équipées de processeurs très puissants. Le plus souvent les disques ne sont pas choisis en rapport avec les qualités du processeur. Leur temps d'accès T est médiocre, le temps moyen d'exécution petit puisque le processeur est rapide, s est donc grand et les performances sont alors très dépendantes de la taille de la mémoire, seul moyen de diminuer la probabilité p d'un défaut de page. Il faut donc configurer ces machines avec une grande mémoire afin de solliciter au minimum la pagination.
d'utilisation du processeur varie en fonction de ce rapport et de la probabilité p qu'un défaut de page se produise. p est déterminée par les caractéristiques des programmes qui s'exécutent et la taille de la mémoire. Pour une valeur donnée de p, ce graphique montre comment s'écroule lorsque s augmente. Ceci montre combien il serait catastrophique d'attacher à une machine rapide des disques à accès lent: T serait grand donc s également. Ceci doit être pris en compte, à l'heure actuelle, alors qu'on trouve sur le marché à un prix très raisonnable, des stations de travail équipées de processeurs très puissants. Le plus souvent les disques ne sont pas choisis en rapport avec les qualités du processeur. Leur temps d'accès T est médiocre, le temps moyen d'exécution petit puisque le processeur est rapide, s est donc grand et les performances sont alors très dépendantes de la taille de la mémoire, seul moyen de diminuer la probabilité p d'un défaut de page. Il faut donc configurer ces machines avec une grande mémoire afin de solliciter au minimum la pagination.
Ces considérations montrent combien le fonctionnement d'une machine à mémoire virtuelle paginée est sensible à son profil d'utilisation. Lorsqu'on trace la courbe qui représente en fonction du nombre n de processus actifs (fig. 5.16a) on voit qu'il existe une valeur optimale lorsque on a chargé suffisamment de processus pour employer entièrement le processeur. Mais rapidement, les performances s'écroulent lorsqu'on dépasse ce seuil. L'ordinateur passe alors le plus clair de son temps à paginer les programmes qui sont en cours d'exécution. Le temps de réponse moyen  augmente alors très rapidement (fig. 5.16b).
augmente alors très rapidement (fig. 5.16b).
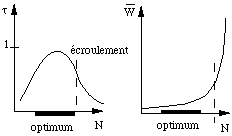 |
figure 5.16 : Taux d'utilisation (a) et temps
de réponse (b) en fonction du nombre de processus |
Pour éviter une dégradation des performances il faut ne pas dépasser ce nombre optimum n de processus concurrents. Ce réglage dépend de l'usage de l'ordinateur et ne peut être fait qu'empiriquement. Certains systèmes utilisent un mécanisme de file d'attente pour retarder cette échéance. Un nombre limité de processus est actif, les autres sont mis dans une file d'attente. Ceci n'est pas très agréable pour leurs propriétaires mais, outre le fait que ce sont ceux qui ont consommé le plus de temps de calcul qui se trouvent dans cette situation, cela évite des variations brutales et désagréables du temps de réponse. On peut également imposer un temps maximum de calcul à tous les processus interactifs et swapper les plus anciens.
Ce problème est très sensible pour Unix où chaque utilisateur peut créer un nombre important de processus. On arrive rapidement à une situation de blocage. Ce fut d'ailleurs l'effet du premier virus Internet connu. Sur les plates-formes Unix où il était installé, sa seule fonction était de se multiplier en créant de nouveaux processus. La zone optimale de fonctionnement de la figure 5.16 fut rapidement dépassée et les machines virent leurs performances s'écrouler. Ceci peut se produire également lorsqu'on utilise l'environnement multi-fenêtres X-Window. A chaque fenêtre sont associés un ou plusieurs processus et ceci multiplie donc leur nombre par utilisateur. C'est pourquoi il faut dimensionner beaucoup plus largement la mémoire lorsqu'on emploie ce type de terminal. On estime qu'il faut ajouter 8 à 10 Moctets de mémoire centrale par écran.
Ces considérations concernent essentiellement le responsable de l'exploitation. Cependant le programmeur peut limiter les défauts de page dans ses applications en essayant de respecter le principe de localité.
Un programme de grande taille peut s'exécuter de façon harmonieuse à condition d'utiliser des pages contiguës, dans ses segments de code comme de données, pendant le temps le plus long possible. Au niveau du langage évolué employé, cela signifie qu'on évitera les débranchements : il peut être intelligent de remplacer des boucles par des répétitions d'instructions (les compilateurs possèdent souvent des options qui le font automatiquement), de ne pas multiplier les appels à des fonctions pour éviter les débranchements à des adresses qui provoqueraient un défaut de page et d'accéder aux tableaux dans leur ordre de rangement : colonne par colonne en Fortran, ligne par ligne en langage C. Ceci n'est évidemment pas toujours possible. La clarté de l'écriture doit toujours être privilégiée. Cependant il est intéressant de lire attentivement les manuels des compilateurs et les guides d'optimisation fournis par les constructeurs. Il existe de nombreuses options qui permettent de façon automatique, à partir d'un code bien écrit, de réaliser ces recommandations. Les codes des fonctions sont automatiquement ajoutés à l'endroit de leur appel, des boucles sont remplacées par des séries d'instructions... Le gain de performance peut être considérable.
Copyright Yves Epelboin, université P.M. Curie, février 2003, MAJ
21 avril, 2006
