Imaginons plusieurs processus qui demandent également à calculer. Dans une machine monoprocesseur ils doivent se partager cette ressource unique. Ces processus, appelés clients, sont mis dans une file d'attente et le service demandé leur est fourni tour à tour, en fonction de critères de gestion spécifiques à la file. Plusieurs situations peuvent se produire (fig. 5.2) :
- la demande d'un processus est entièrement satisfaite. Il n'a plus besoin du processeur. Dans ce cas il quitte la boucle et disparaît.
- la ressource est déjà utilisée par un autre processus. Il attend.
- La ressource est réquisitionnée par un processus plus prioritaire. Le processus actif est remis dans la file d'attente.
Le scheduler gère la file d'attente. Il analyse les demandes qui arrivent et les place dans la file. Le dispatcher suit l'activité du processeur, il choisit la requête à traiter et l'extrait de la file. Il gère donc l'allocation du processeur. Il peut le réquisitionner en fonction de la priorité des processus demandeurs et du temps déjà consommé par celui qui est en cours d'exécution.
Le temps de réponse d'un système, c'est à dire le temps qui s'écoule entre entrée et sortie de la file d'attente, est fonction de la politique choisie par le dispatcher et de la disponibilité de la ressource.
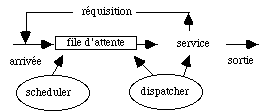
figure 5.2 : Gestion du processeur par le scheduler et le dispatcher
Nous allons évoquer trois politiques possibles :
- le modèle FIFO (First In First Out) où le dispatcher alloue le processeur au processus arrivé le premier dans la file d'attente. C'est l'exemple de la file d'attente à un arrêt de taxi.
- le modèle SJF (Shortest Job First) qui sert de façon prioritaire la requête qui demande le moins de temps au processeur.
- le modèle du tourniquet où il existe plusieurs files d'attente.
Le modèle FIFO
Le premier processus entré dans la file d'attente est le premier servi. Dans un modèle aussi simple il est impossible de gérer des processus de priorité différente car la file est unique. Ce modèle est par contre bien adapté au partage du processeur par des processus de même priorité. Il faut alors créer autant de files que de niveaux différents. Nous allons l'étudier dans le cas du temps partagé où tous les processus utilisateurs possèdent la même priorité. Pour simplifier, nous supposerons que la tranche de temps allouée à chaque processus est constante, ce qui est évidemment très simplificateur et ne permet pas de généraliser cette étude à d'autres cas.
Soit  le temps d'attente moyen ou temps de réponse. Ceci est le temps qui sépare l'instant où une demande est faite, après avoir frappé une commande sur le clavier, de celui où l'ordinateur répond à cette requête. Des études ont montré qu'au-delà d'une seconde l'impression psychologique est désastreuse. Appelons
le temps d'attente moyen ou temps de réponse. Ceci est le temps qui sépare l'instant où une demande est faite, après avoir frappé une commande sur le clavier, de celui où l'ordinateur répond à cette requête. Des études ont montré qu'au-delà d'une seconde l'impression psychologique est désastreuse. Appelons 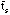 le temps moyen de service alloué à chaque processus, 1/
le temps moyen de service alloué à chaque processus, 1/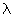 le temps moyen qui sépare l'arrivée de deux requêtes consécutives, en provenance de deux processus différents, dans la file d'attente. Le temps d'attente augmente lorsque les requêtes se font plus nombreuses et la saturation se traduit par:
le temps moyen qui sépare l'arrivée de deux requêtes consécutives, en provenance de deux processus différents, dans la file d'attente. Le temps d'attente augmente lorsque les requêtes se font plus nombreuses et la saturation se traduit par: 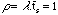 .
.  est la charge de l'ordinateur. Ce nombre est sans dimension.
est la charge de l'ordinateur. Ce nombre est sans dimension.
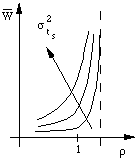 |
figure 5.3 : Evolution de la charge
Modèle FIFO |
La figure 5.3 montre qualitativement la variation du temps d'attente en fonction de la charge. Lorsque 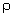 atteint 1 le temps séparant l'arrivée des requêtes devient égal au temps moyen de service. Le processeur est constamment employé. Si la demande augmente encore la file d'attente s'allonge, la saturation est dépassée et le temps de réponse croît alors très rapidement. En réalité les temps de service demandés ne sont pas égaux car certains processus sont interrompus par une demande d'entrées/sorties. On caractérise leur dispersion par l'écart-type
atteint 1 le temps séparant l'arrivée des requêtes devient égal au temps moyen de service. Le processeur est constamment employé. Si la demande augmente encore la file d'attente s'allonge, la saturation est dépassée et le temps de réponse croît alors très rapidement. En réalité les temps de service demandés ne sont pas égaux car certains processus sont interrompus par une demande d'entrées/sorties. On caractérise leur dispersion par l'écart-type 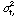 de leur distribution qui est poissonienne. Les différentes courbes représentées dans la figure 5.3 montrent la dégradation du temps de réponse en fonction de cette dispersion. augmente avec , ce qui est fâcheux car par nature un usage interactif signifie des demandes de temps de service très dispersées. Ce modèle simple montre déjà combien il est difficile de prévoir la tenue en charge d'un ordinateur car il est extrêmement délicat de simuler la répartition des demandes. On constate que le modèle de file d'attente FIFO a l'inconvénient de ne plus répondre de façon satisfaisante lorsqu'on approche de la saturation. Un ordinateur peut alors donner l'impression d'être bloqué puisque les temps de réponse tendent vers une limite asymptotique infinie.
de leur distribution qui est poissonienne. Les différentes courbes représentées dans la figure 5.3 montrent la dégradation du temps de réponse en fonction de cette dispersion. augmente avec , ce qui est fâcheux car par nature un usage interactif signifie des demandes de temps de service très dispersées. Ce modèle simple montre déjà combien il est difficile de prévoir la tenue en charge d'un ordinateur car il est extrêmement délicat de simuler la répartition des demandes. On constate que le modèle de file d'attente FIFO a l'inconvénient de ne plus répondre de façon satisfaisante lorsqu'on approche de la saturation. Un ordinateur peut alors donner l'impression d'être bloqué puisque les temps de réponse tendent vers une limite asymptotique infinie.
Modèle SJF
Dans le modèle SJF (Shortest Job First) appelé aussi "le plus court d'abord" le scheduler utilise le temps de réquisition de la ressource (ou son estimation) comme critère de priorité. Les demandes les plus courtes sont satisfaites d'abord, donc ce sont les processus qui demandent le moins de temps du processeur qui sont servis les premiers. On remarquera que, à la différence du modèle précédent, on suppose que cette information est connue avant l'exécution. Ce modèle est bien adapté à la description du traitement par lot où l'on doit préciser, lorsqu'on soumet une requête, le temps maximum de calcul. Le travail le moins demandeur est servi le premier.
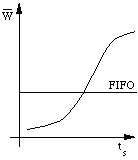 |
figure 5.4 : Evolution du temps d'attente
dans le modèle SJF |
La figure 5.4 montre comment le temps de réponse varie en fonction du temps demandé, à charge constante, c'est à dire pour une valeur fixe de . Dans ce graphique, un point d'une courbe de la figure 5.3 du modèle FIFO, correspond à une droite horizontale. Plus augmente plus cette droite se trouve dans le haut du graphique. La comparaison des courbes montre que la politique SJF est favorable aux travaux les plus courts mais est mauvaise pour les plus longs. De plus, si le temps moyen entre les arrivées des requêtes courtes diminue (c'est à dire si augmente), les travaux les plus longs risquent de rester éternellement en file d'attente et ne seront jamais exécutés. Ceci est quasiment la situation que l'on vit dans une file d'attente de téléski aux heures de pointe lorsque les écoles de ski prioritaires se présentent: il n'y a plus aucun espoir de passer. La seule possibilité est alors de forcer la priorité pour pouvoir donner aux processus leur temps de service. C'est le rôle du scheduler
Le problème est identique pour les systèmes de gestion d'imprimantes sophistiqués. Imprimer les travaux les plus courts peut bloquer, en cas de saturation, les impression les plus longues. On corrige ce défaut en augmentant régulièrement la priorité des travaux les plus longs, en fonction du temps qu'ils ont déjà passé dans la file d'attente, jusqu'à dépasser celle des plus petits. Dans tous les cas la méthode SJF ne peut être employée que lorsqu'on peut estimer par avance la demande de la ressource.
Le modèle du tourniquet
Le modèle du tourniquet ou round robin représente assez bien une politique d'allocation du processeur pour le temps partagé, plus sophistiquée que le premier modèle évoqué.
On alloue au processus, placé en tête de la file d'attente FIFO F0, un quantum de temps Q0. Si ce processus est interrompu par une demande d'entrées-sorties, avant la fin de ce quantum de temps, il est renvoyé dans F0. Le processeur est alors alloué au processus suivant placé en tête de F0. Lorsque le processus n'a pas fini son calcul, à la fin du quantum Q0, le processeur est réquisitionné par le dispatcher qui l'alloue au processus placé maintenant au début de la file d'attente F0. Jusque là le schéma n'est pas différent du modèle FIFO que nous avons déjà décrit dans la figure 5.1.
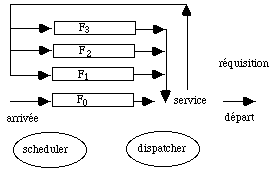
figure 5.5 : Allocation du processeur dans le modèle du tourniquet
En réalité le système de gestion possède N files d'attente. A son arrivée le processus a été rangé dans la file la plus prioritaire F0. Lorsqu'il a épuisé son quantum de temps Q0 , il est rangé dans la file F1 moins prioritaire. Lorsqu'un processus de cette file est activé (ce qui ne se produit que lorsque F0 est vide), le système lui alloue un quantum de temps Q1. S'il n'est pas encore terminé à la fin de ce deuxième quantum, il est rangé dans la file F2 affecté du temps Q2. Une file de rang i ne peut être servie que si toutes les files précédentes sont vides. Le quantum Qi augmente avec i, donc en raison inverse de la priorité. Un processus qui a traversé toutes les files sans épuiser son temps de service reste dans la file la moins prioritaire. La figure 5.5 schématise ce fonctionnement.
Si Q0 est grand on peut quasiment considérer que tous les travaux courts, dont le temps de service ts est plus petit que Q0 seront totalement satisfaits en une seule fois et jamais remis dans la file d'attente. Ceci correspond alors pratiquement au modèle SJF car les travaux les plus courts sont servis les premiers.
La priorité des travaux les plus courts est la plus grande mais en réglant les priorités des différentes files de façon plus subtile que celle que nous venons de décrire, on peut éviter les phénomènes de famine pour les processus demandant un temps long.
Copyright Yves Epelboin, université P.M. Curie, février 2003, MAJ
30 mars, 2006
