La notion de batch a peu à voir avec la terminologie employée par DOS qui évoque un enchaînement de commandes inscrites dans un fichier. Sous Unix cela s'appelle un script.
Le traitement par lot ou batch est employé lorsqu'un programme ne demande pas de dialogue avec un opérateur humain. Comme il est inutile de mobiliser un terminal on remplace celui-ci par des fichiers, au minimum deux, l'un utilisé pour lire les données qui y ont été enregistrées à l'avance, l'autre pour les écritures et remplacer l'écran qui est donc libéré l'écran pour un autre usage. Le travail se déroule en arrière plan ou background. Unix, Windows XP Professionnal possèdent cette facilité. Le batch se déroule à une priorité réduite par rapport à l'usage interactif de la machine car un être humain est moins sensible à un allongement du délai de restitution d'un travail lorsqu'il peut employer son temps à autre chose que lorsqu'il attend devant son terminal la réponse de l'ordinateur à la requête qu'il vient de frapper sur son clavier.
Un calcul en batch peut attendre et l'on privilégie les usages interactifs. Il est donc moins prioritaire mais la tentation est grande de lancer le même programme à partir d'un terminal pour profiter de la priorité donnée à l'interactivité, même lorsqu'elle n'existe pas! Pour éviter que les usagers interactifs n'abusent de leurs privilèges en exécutant dans cet environnement des tâches qui dialoguent fort peu et ne nécessitent donc pas l'usage d'un terminal, on peut imaginer plusieurs améliorations. La première, souvent utilisée dans les systèmes Unix, est de limiter l'usage du processeur : lorsqu'un processus interactif calcule plus qu'un temps maximum fixé par l'administrateur il est arrêté. Les gros calculs ne peuvent donc être exécutés qu'en traitement par lot.
Une méthode plus subtile est de réduire progressivement la priorité d'un processus interactif lorsqu'il ne fait que calculer (fig. 5.1).
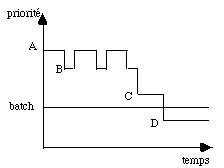 |
figure 5.1 : Exemple de gestion des priorités
du batch et de l'interactif |
Celle-ci ne redevient normale que lorsqu'une entrée-sortie se produit. On peut même régler le système pour que la priorité tombe en dessous de celle du batch. Le fait de tenter d'exécuter en interactif un travail qui n'en relève pas devient alors franchement pénalisant et cela peut bloquer les abus. Dans le schéma de la figure 5.1 un travail interactif commence avec une priorité A supérieure à celle du batch. Elle est réduite au niveau B s'il calcule trop longtemps mais remonte au niveau A dés qu'il effectue une entrée-sortie. Enfin si les calculs sans dialogue se poursuivent trop longtemps, la priorité décroît au niveau B puis C et enfin D où il se trouve pénalisé puisque le batch est alors plus prioritaire.
Unix ne possède, en natif, que des possibilités rudimentaires de batch. On peut, par la commande at, déclencher le démarrage d'une application à une heure donnée, sans connexion de son utilisateur sur un terminal. Il existe des produits plus élaborés dans le domaine public ou chez des fournisseurs. Les requêtes sont placées dans des files d'attente en fonction de critères propres au centre de traitement : taille mémoire demandée, temps maximum de calcul prévu, quantité d'entrées-sorties... Le responsable du système déclenche les files d'attente soit manuellement soit automatiquement en fonction de la charge. Il est même possible de distribuer les requêtes sur un ensemble de machines connectées en réseau qui partagent leurs disques. En pratique ces possibilités ne sont implantées que dans des centres qui sont amenés à gérer de gros calculs c'est à dire dans le domaine scientifique essentiellement.
Copyright Yves Epelboin, université P.M. Curie, février 2003, MAJ
8 mars, 2006
