Le principe de localité, c'est à dire la constatation empirique du fait que les programmes manipulent essentiellement des pages contiguës, a amené les constructeurs à introduire une hiérarchie dans les mémoires des ordinateurs. Lorsque le processeur accède à une adresse n, il est statistiquement probable qu'il réclamera une adresse voisine pour des instructions ou les variables suivantes.
Une politique idéale de gestion dynamique d'une hiérarchie de mémoire est de répartir les informations nécessaires au fonctionnement d'un processus de telle façon qu'elles soient disponibles sans retard ni interruption au moment voulu à l'endroit désiré. Imaginons deux niveaux adjacents de cette hiérarchie. Une bonne gestion anticipera donc les besoins en amenant du niveau bas au niveau haut le sous-ensemble d'informations dont la probabilité d'accès est la plus élevée. Le niveau haut fonctionne donc comme un cache pour le niveau bas. Ceci est parfaitement conforme au principe de localité.
La mémoire de stockage la plus rapidement accédée est dans le processeur lui-même : il s'agit des registres. Un compilateur sait reconnaître, par exemple, les deux séquences suivantes placées à une distance de quelques instructions :
a = b + c; .......... d = a + f;
Ranger à l'adresse de a le résultat de la première instruction puis rappeler cette même adresse pour exécuter la seconde nécessite deux transferts entre le processeur et la mémoire. Le compilateur traduira ce code en :
$R = b + c; ........... d = $R + f; a = $R;
où $R symbolise un registre. La même séquence demande un transfert de moins.
Le deuxième niveau de mémoire est constitué par les caches de code et de données attachés au processeur. Il y accède sans utiliser le bus (dans les processeurs modernes le cache L1 est intégré dans la puce). Lors d'une demande de chargement d'une instruction ou d'une donnée, le processeur vérifie que l'information n'est pas déjà dans un cache. Si oui il abandonne cette demande, sinon il procède normalement. Comme la préparation d'un transfert est plus longue que le transfert lui-même, il déplace simultanément tout un bloc d'instructions ou de données qui sont copiés dans les caches pour être éventuellement utilisées au cours des cycles suivants. Le calcul est très fortement accéléré tant qu'on travaille dans ces mémoires. Les gains de performance peuvent atteindre 2 ou 3. La taille des caches doit être en relation avec la puissance du processeur et du temps nécessaire aux échanges sur le bus : trop petits ils ne suffisent pas à alimenter un processeur rapide qui est alors souvent interrompu par des accès forcément plus lents à la mémoire. Des variations de 2 à 3 dans la vitesse d'une machine peuvent être mesurées en fonction de ce paramètre. Ceci est bien évidemment très dépendant des programmes. L'utilisateur peut optimiser le code de son programme pour exploiter au mieux cette possibilité. Il faut, entre autre, couper les boucles trop longues en plusieurs de façon que chacune tienne dans le cache, manipuler des éléments de tableaux voisins et de façon plus générale respecter le principe de proximité.
Aux niveaux les plus bas on trouve la mémoire puis les disques. Les tampons utilisés pour les entrées-sorties sont les caches des disques. Les coupleurs de bonne qualité comportent également une mémoire locale qui joue également un rôle dans cette hiérarchie. Cet ensemble est résumé dans la figure 5.17. Les numéros indiquent la position hiérarchique de la mémoire considérée.
Les ordinateurs qui doivent manipuler de grosses bases de données disposent de disques qui sont eux-mêmes de véritables machines. La mémoire de ces dernières joue le rôle de cache afin de limiter les accès aux disques qui sont trop lents. C'est là qu'on recherche d'abord l'information. Lorsqu'elle ne s'y trouve pas, on la lit sur un disque c'est tout un bloc qui est transféré et placé dans la mémoire de la machine de stockage.
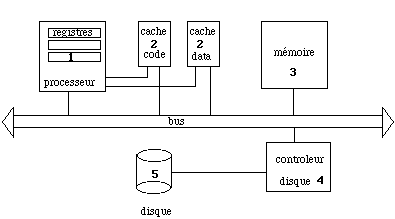
Figure 5.17 - La hiérarchie des mémoires dans un ordinateur
L'utilisation de caches ne présente pas que des avantages. Ceci complique le chargement du contexte d'un processus puisqu'il faut tenir compte du contenu de ceux-ci. Les transferts avec la mémoire sont moins efficaces car il faut consulter leur contenu et les charger en parallèle le cas échéant. C'est la raison pour laquelle les machines Cray n'en possèdent pas. Recherchant les performances les plus grandes ce constructeur a préféré employé des technologies de pointe plus coûteuses que ralentir le fonctionnement. En fait la mémoire de ces machines n'est qu'un très grand cache mais cette solution est onéreuse.
Comme toujours en informatique la réalisation d'une machine et de son système d'exploitation est un compromis entre efficacité, complexité et coût.
Copyright Yves Epelboin, université P.M. Curie, février 2003, MAJ
15 mars, 2006
