Architecture
Le noyau représente l'interface entre les applications et l'électronique de la machine. Il doit donc être écrit en fonction de ses caractéristiques hardware.
Il contient les fonctions nécessaires à :
- la gestion de la mémoire et à ses échanges avec le processeur
- accès aux périphériques. Dans Unix les drivers de niveau bas sont en général inclus dans le noyau, ce qui fait qu'il faut le recompiler lorsqu'on veut en ajouter un ou le modifier. Les noyaux Unix contiennent donc souvent les drivers pour les périphériques les plus usuels. Dans les dernières versions de Linux il est possible, selon ses besoins, de les intégrer ou non à celui-ci.
- la gestion temps réel de la machine
- la gestion des processus
- la gestion des systèmes de fichiers au niveau le plus bas (inodes et swap)
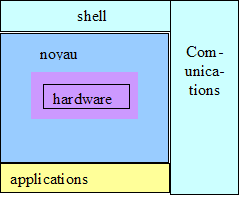
Figure 1 : architecture d'Unix
- Les shells réalisent l'interface entre les utilisateurs et le noyau. C'est à travers eux que l'utilisateur passe des commandes à l'ordinateur. Il en existe plusieurs que l'on peut changer suivant ses besoins. C’est là un des aspects les plus troublants de ce système. En fonction du shell employé, de la définition de son environnement on arrive à des fonctionnements en apparence assez différents. Cela fait la joie de l’informaticien qui peut tailler la machine à ses désirs, moins celle de l’utilisateur ordinaire qui est souvent perdu à travers les différentes variantes de fonctionnement qui lui sont proposées. L’usage d’environnements plein écran, inspirés du monde des micro-ordinateurs, permet de standardiser plus ou moins l’apparence. Des tentatives d’uniformisation ont été tentées par les constructeurs à travers CDE (Common Desktop Environnement) mais n’ont pas vraiment abouties. Dans le monde Linux KDE et Gnome sont aujourd’hui deux alternatives qui se développent.
Les applications regroupent les fonctions les plus diverses :
- les outils de base comme les compilateurs, les éditeurs …
- les outils spécialisés : bureautique, scientifique….
- Les bibliothèques
Les communications constituent un ensemble en soi. Dès le début des années 18980 les systèmes Unix présentaient l’ensemble des fonctionnalités du monde TCP/IP intégrées. Il est donc justifié de les considérer comme une partie inséparable de l’ensemble des fonctionnalités.
Cette architecture en coquille explique pourquoi Unix peut être porté sur n’importe quelle architecture matérielle. Il suffit de changer le noyau sans toucher, en principe, à aucune autre fonctionnalité. Pour la première fois on dispose donc d’un système commun à toutes les machines, depuis le PC équipé de processeurs Pentium, jusqu’aux machines géantes, massivement parallèles (IBM, Silicon Graphics…) ou vectorielles (Cray, Fujitsu…). Il existe néanmoins de sérieuses limitations dans cette compatibilité sur lesquelles nous reviendrons.
Caractéristiques générales d’Unix
Les fichiers
Les fichiers Unix, du point de vue de l’utilisateur, ne se différentient guère de ceux que l’on rencontre sur les micro-ordinateurs sous Windows ou MacOS. Les répertoires ou directories sont symbolisés sous forme de dossiers dans les interfaces graphiques, la structure est arborescente : le dossier de base représente le tronc de l’arbre, les branches sont les sous-dossiers, les fichiers les feuilles. Comme sous Windows, on peut créer des raccourcis ou liens symboliques pour désigner rapidement un objet enfoui dans les profondeurs de l’arbre… La structure sousjascente est néanmoins fort différente et ne ressemble en rien à ce que l’on rencontre sur les micro-ordinateurs. Elle permet de manipuler rapidement des fichiers de grande taille, elle évite la nécessité du défragmentage indispensable sous Windows, elle intègre depuis toujours les éléments de contrôle d’accès qui ne sont apparus qu’avec Windows NT et MacOS10. Le système comprend un nombre impressionnant de commandes de manipulation, de recherche et d’analyse du contenu des fichiers. Les primitives d’accès et la gestion des buffers d’interface permettent d’accéder efficacement aux informations.
La structure des systèmes de fichiers est très élaborée : Unix est un système à mémoire paginée virtuelle qui emploie pour cela une partition formattée de façon spéciale, complètement séparée des autres systèmes de fichiers. Toutes les réalisations d’Unix aujourd’hui intégrent une couche spéciale d’accès au support physique, « Journalised File System ou JFS » qui permet en cas de crash ou d’arrêt intempestif de récupérer rapidement un état valable des informations sur le support. Certains systèmes permettent également d’étendre un système de fichiers (ou partition) sur plusieurs disques physiques.
Les processus
Unix est basé sur les processus. A chaque fois qu’un utilisateur tape une commande, lance un programme il crée, sans le savoir un processus. Comme Unix est un vrai système multi-tâches il est possible de piloter cette activité de façon fine, même lorsqu’on est un usager ordinaire : un processus et celui qui a servi à le créer peuvent travailler en parallèle, le père (le processus initiateur) peut attendre le fils…
Au démarrage du système, un premier processus, init, est créé. Puis progressivement celui lance d’autres processus, chacun responsable d’une fonction. Certains ont une durée de vie brève, employés à l’initialisation du système uniquement, d’autres vont rester actifs ou en veille pendant toute la durée d’activité de l’ordinateur. Il est intéressant de regarder, lorsque la phase de démarrage est terminée, l’état des processus : on peut observer l’existence de quelques dizaines de processus en activité ou en attente, on peut voir les traces de plusieurs dizaines, voire de plus de cent processus qui ont n’ont vécu que le temps du démarrage. Lorsqu’on remonte la filiation de tous les processus on retrouve toujours le premier père, le processus init.
Parmi les nombreux processus en activité il existe une catégorie spéciale qui porte l’étrange nom de démons, mauvaise traduction française du nom américain daemon. Il s’agit de processus qui fonctionnent sans disposer ni d’un terminal ni d’un clavier qui leur sont affectés et qui acquièrent leurs informations par d’autres moyens.
Unix emploie abondamment le principe du client-serveur. Celui-ci a été introduit pour éviter les problèmes de verrous mortels difficiles à résoudre.
Rappelons son principe de fonctionnement. Pour cela imaginons une boutique avec un vendeur, derrière son comptoir, qui attend les clients. Ceux-ci se présentent à leur tour, réclament leur article et le vendeur les sert ou leur indique, le cas échéant, qu’il ne dispose de l’article désiré.
Remplaçons le terme vendeur par serveur et nous avons une parfaite analogie dans le cas d’un système informatique. Un processus client C envoie une requête au processus serveur S (fig. 1a). Celui-ci dispose d’une file d’attente dans laquelle les demandes des clients sont placées puis servies une à une. Lorsque vient son tour le serveur gère la demande de C et lui renvoie le résultat correspondant à sa requête.
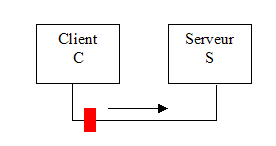
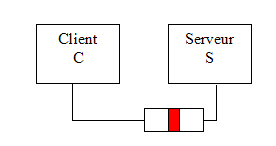
C envoie une requête au serveur S La requête est placée en attente
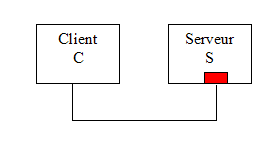
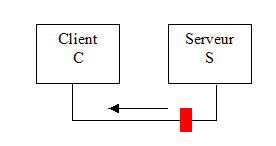
La requête est traitée à son tour La réponse est renvoyée au client
Les entrées-sorties
Les entrées-sorties sous Unix sont particulièrement souples. On associe aux processus des flôts non structurés qui sont traités dynamiquement en fonction du périphérique choisi. Par exemple, il est très facile de remplacer le clavier (flôt 0 ou stdin) par un fichier, les flôts de sortie 1 (stdout vers l'écran) et 2 (flôt des erreurs stderr vers l'écran également) vers des fichiers séparés ou vers le stdin d'un second processus. On peut ainsi enchaîner les processus, le flôt de sortie de l'un servant de flôt d'entrée pour le suivant, ce qui permet une programmation modulaire extrèmement puissante.
Il n'existe pas une grande différence lorsqu'on programme l'usage de fichiers, des échanges entre processus par pseudo fichiers en mémoire ou pipes ou les sockets qui permettent la communication à travers le réseau en employant le protocole TCP/IP.
Cette souplesse est l'un des points forts de ce système. Par contre l'inconvénient est qu'il n'existe aucun moyen de relire une information placée sur un disque sans connaissance extèrieure de la structure des données qui ne sont qu'un flot continu d'octets.
Les langages de commandes
A la différence des autres systèmes, Les langages de commande sont nombreux. Les shells sont vus comme des interfaces entre l'utilisateur et le noyau du système. Il est même extrèmement simple de développer le sien propre et les informaticiens s'en sont donnés à coeur joie. Les shells sont non seulement un langage de commande mais permettent de réaliser des scripts extrèmement puissants qui possèdent toutes les caractéristiques des langages de programmation : boucles, contrôles et tests... Ils sont abondamment employés pour le fonctionnement du système d'exploitation lui-même.
Historiquement le premier shell fût le Bourne Shell, maintenant pratiquement abandonné, puis le C shell qui lui ressemblait beaucoup mais introduisait un historique et un éditeur ligne qui permet de rappeler et de modifier une commande employée antérieurement. Aujourd'hui Linux enploie le bash qui est un avatar du Korne Shell. Tout ceci est perturbant pour l'usager ordinaire qui peut se trouver assez ennuyé lorsqu'il veut installer un programme assez ancien faisant appel à un shell obsolète.
Plus récemment, sous la pression de smicro ordianteurs, de Windows et MacOS, des interfaces graphiques ont été développés : KDE et Gnome notamment, mais il n'en reste pas moins que l'emploi des commandes au travers de l'interface ligne à ligne des shells reste nécessaire.
Syntaxe des commandes
Bien qu’Unix offre, comme tout système moderne, des interfaces qui permettent de réaliser les commandes essentielles au moyen de la souris, il s’avère souvent utile de pouvoir employer les commandes ligne à ligne en ouvrant une fenêtre qui émule un terminal conventionnel. La syntaxe des commandes est standardisée. Elle est de la forme :
commande [-par1 –par2 ….] [nom 1 nom 2]
Les paires de crochets signifient que ces paramètres sont optionnels, selon la commande. Ceux précédés de – définissent des paramètres et leurs valeurs éventuelles. Les noms sont ceux de fichiers sur lesquels portent la commande.
Par exemple :
- ls liste des noms de fichiers rangés dans un répertoire
- ls – a liste de tous les fichiers y compris les fichiers cachés.
- ls –l fichier liste des attributs du fichier de nom « fichier ».
Il existe des jokers qui permettent de définir une suite de caractères :
* signifie n’importe quelle combinaison de caractères
? signifie n’importe quel caractère rangé à la place de ce symbole.
Par exemple ls *.c retournera la liste de tous les fichiers dont le nom se termine par les caractères « .c », ls -l t ?t ?.c retournera aussi bien les caractéristiques de s fichiers toto.c, toti.c que tita.c…
Copyright Y. Epelboin, 2004, université P.M. Curie, MAJ
18 mars, 2006
