Etudions maintenant comment les liaisons sont réalisées dans la pratique. Windows ayant repris les principes déjà employés par Unix (et par d'autres avant lui) il y aura peu à en dire. De plus, comme tout le mécanisme est dissimulé par l'interface graphique, il est, la plupart du temps invisible.
Organisation d'un système de fichiers
Les fichiers sont regroupés dans des unités logiques appelées système de fichiers. Il correspond à un espace physique qui s'étend sur une partie d'un disque ou plusieurs disques. Pour l'utilisateur il apparaît comme un disque C:, D: ... sous Windows, avec un nom choisi à sa création pour Unix. Nous y reviendrons plus en détails dans la section suivante.
Le fichier est l'unité de conservation de l'information. C'est un objet complexe qui n'est pas constitué uniquement des informations visibles par l'utilisateur. Son descripteur contient les informations nécessaires à sa localisation physique sur le disque et à son usage. Le nom de ce descripteur est interne, c'est à dire que l'utilisateur ne le connaît pas. Il n'accède au fichier que par son nom externe. La liaison entre ces deux noms est établie au moyen du catalogue.
Un fichier peut éventuellement être défini par un nom local à la procédure en cours d'utilisation. C'est ce qui est fait lors de l'appel à la primitive d'ouverture dans un langage de programmation. Cette méthode est plus efficace que l'usage du nom externe car son interprétation est plus rapide et peut apporter une plus grande souplesse dans la gestion du fichier.
Ces différentes possibilités sont résumées dans la figure 4.5.
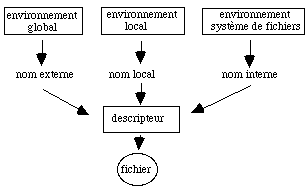
figure 4.5 - Les différents noms d'un fichier
On rencontre le plus souvent trois modèles de catalogue:
- organisation en un seul niveau (fig. 4.6): on associe directement le descripteur aux noms externes. Il n'y a aucun classement possible aussi ce système n'existe pratiquement plus.
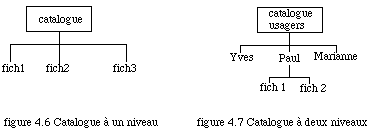
- organisation à deux niveaux (fig. 4.7) : il existe des catalogues secondaires par utilisateur. Certains systèmes comme ceux propres à IBM emploient des structures à un niveau qui ressemblent aux structures à deux niveaux. Les règles d'écriture dans le catalogue imposent un nom à plusieurs champs séparés par des points, le premier étant l'identificatif de l'utilisateur. Les mécanismes de sécurité interdisent à une personne de retrouver les éléments du catalogue qui ne correspondent pas à ses propres fichiers, sauf autorisation explicite.
- organisation arborescente (fig. 4.8) :
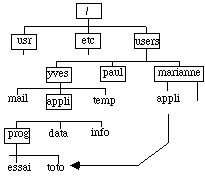
figure 4.8 : catalogue arborescent
C'est la plus connue de nos jours puisqu'elle est utilisée par Unix et les systèmes qui s'en sont inspirés (DOS puis Windows...).
Unix
On peut créer un système à autant de niveaux de répertoires que désiré (il existe cependant des limitations pratiques suivant les systèmes). Un répertoire ou directory possède un père : il s'agit du répertoire de niveau plus élevé dans la hiérarchie et un ou plusieurs fils, fichiers ou répertoires plus bas dans l'arborescence. Le répertoire de niveau le plus élevé est appelé racine. Il porte le nom du système de fichiers. Il ne possède pas de père. Nous utiliserons ici Unix comme exemple.
/nom_systeme désigne le répertoire racine par son nom : nom_systeme. Dans les systèmes Unix on crée, le plus souvent, un système de fichiers sans nom désigné par /.
Rappelons que sous Windows il s'agit d'une lettre C:, D:.. et que le nommage, par défaut, est dynamique, ce qui signifie qu'il peut changer si on introduit une nouvelle unité de stockage.
Le nom d'un répertoire est construit en donnant sa filiation : /users/yves/appli1 par exemple (fig. 4.8). Par convention . désigne le répertoire courant, appli1 dans cet exemple, .. le répertoire père, yves dans ce même exemple.
On peut établir des liens symboliques (ou raccourcis sous Windows) pour désigner un fichier, par exemple entre appli et toto. appli n'est pas un véritable objet mais un simple pointeur dans le répertoire marianne qui désigne l'objet toto qui se trouve sous prog. Le système établit un lien qui permet un accès facile, à partir des deux répertoires, du même objet. On peut créer des liens entre fichiers comme entre répertoires.
Dans la plupart des systèmes d'exploitation on peut introduire un suffixe séparé par un point, dans les noms de fichiers. Leur signification varie avec le système: .com ou .exe désigne un module exécutable pour Windows, .f pour une source fortran, .c pour une source en langage C, .o est un module compilé pour Unix. Le choix des suffixes est le plus souvent dépendant de l'application ou du compilateur qui utilise le fichier. La convention pour le Web est d'employer html ou htm pour les fichiers qui contiennent du code HTML.
Le nombre de caractères que l'on peut utiliser pour désigner un objet dépend du système d'exploitation. Windows est un exemple hybride curieux : DOS limite les noms à huit caractères + une extension de trois lettres. Comme Windows s'appuie sur DOS les noms plus longs sont rangés et désignés au moyen de fichiers annexes qui contiennent les caractères supplémentaires. Ceci n'est plus vrai pour NT et ses successeurs où la longueur des noms a été allongée.
Mécanismes de nommage
Lorsqu'on travaille sous Unix, le processus qui permet le dialogue entre l'utilisateur et le système d'exploitation, est un shell : bash sous Linux. Il possède, dans son environnement, deux variables qui permettent de nommer aisément les fichiers : HOME et PWD.
Dans l'exemple de la figure 4.8 elle vaut /users/yves par exemple et est configurée automatiquement au lancement du processus. Au début PWD = $HOME
Tout nom de fichier, apparaissant dans une commande, qui n'est pas précédé de /, est complété par la valeur de PWD, $PWD. Ce mécanisme est inhibé si la chaîne de caractères commence par /. Chaque fois que l'on modifie le répertoire courant par la commande CD la valeur de PWD est changée. Par exemple, cd appli/data modifie sa valeur en $PWD + "appli/data".
Liaisons et entrées-sorties
Lorsqu'on écrit un programme il est intéressant de pouvoir distinguer la notion d'entrées-sorties de celle de fichier. Ceci permet de modifier dynamiquement le mode de communication que l'on veut employer en fonction des caractéristiques du support, sans devoir rien changer à la programmation. Ainsi il devient possible de lire les données dans un fichier ou de les frapper directement au clavier, selon son choix, sans avoir à modifier le programme ni devoir le compiler à nouveau. Les systèmes d'exploitation, qui le permettent, possèdent une structure de communication plus générale appelée flot d'entrées-sorties. Lorsqu'un processus est exécutée, on construit cette structure puis on l'affecte à un fichier ou un périphérique dynamiquement au moment voulu. La figure 4.9 résume les trois états possibles de cette structure.
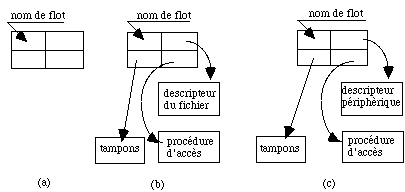
figure 4.9 - Les différents états d'un flot d'entrées-sorties
Avant association (fig. 4.9a) la structure est définie mais aucun lien n'existe. Elle est vide. Les communications sont impossibles car aucun chemin d'accès n'est établi entre cette structure et un objet. Par la suite, elle va servir à définir des pointeurs qui associent le flot d'entrées-sorties à un fichier (fig. 4.9b) ou directement à un périphérique (fig. 4.9b) (écran, clavier...) ainsi que les procédures nécessaires à leur réalisation. Les schémas b et c se ressemblent. Ils ne différent que par la valeur des pointeurs qui désignent des primitives et des tampons différents. Le fait que ces éléments ne soient pas directement contenus dans le programme facilite la gestion dynamique des communications. Le flot possède toutes les caractéristiques d'un organe d'entrées-sorties mais celles-ci ne sont que partiellement déterminées avant affectation.
Pour Unix les noms de flot sont des entiers. 0 désigne le flot d'entrée, 1 le flot de sortie des résultats, 2 le flot de sortie des messages d'erreurs. On les connaît aussi sous les noms standard in ou stdin, standard out ou stdout et standard err ou stderr. On peut associer le flot de sortie d'une première procédure avec le flot d'entrée d'une deuxième au moyen d'un pipe. La liaison utilise un buffer interne.
Une autre possibilité est de dérouter les flots d'entrée et de sortie, qui sont normalement envoyés du clavier et vers l'écran, au moment où le programme est chargé en mémoire pour être exécuté. Appelons le mon_prog. La syntaxe sera:
mon_prog < fic1 > fic2
Le programme lira ses données dans le fichier fic1, écrira les résultats dans le fichier fic2 au lieu d'utiliser le clavier et l'écran. Seules les erreurs éventuelles continueront à être affichées à l'écran car le flot correspondant à stdout n'est pas dérouté. Si on veut le dérouter, à son tour, on écrira :
mon_prog <fic1 > fic2 2>fic_err
Toute combinaison est évidemment légitime.
Copyright Yves Epelboin, université P.M. Curie, 2000, MAJ
30 janvier, 2006
