Organisation logique des fichiers
L'organisation logique à l'intérieur des fichiers ne relève pas rigoureusement des systèmes d'exploitation mais plus souvent des langages et bibliothèques logicielles qui les complètent. Pour Unix la réponse est très simple : il n'existe rien. Les fichiers sont de simples suites d'octets non structurés. Seule la fin de fichier est reconnue. Le reste, c'est à dire la signification des octets qui se succèdent, est l'affaire des langages et des programmations. Ainsi les fichiers écrits en Fortran contiennent des informations dont la structure n'est reconnue que par ce langage. Il n'est même pas garanti que celle-ci soit commune à différentes réalisations du compilateur sur différentes machines.
Néanmoins il est indispensable d'aborder ici le problème des structures de fichiers car la limite entre applicatifs et système d'exploitation est ténue et les fichiers sont une part importante du fonctionnement des ordinateurs. Nous n'évoquerons que les plus classiques car elles sont une bonne illustration de ce qui existe.
Accès séquentiel
Un fichier est constitué d'un ensemble d'informations groupées par articles. Chacun d'eux correspond à une instruction d'écriture dans le programme qui a créé cette information. L'accès est séquentiel si, pour accéder à l'article rangé à la n ème position, il est nécessaire de lire les n-1 articles précédents. Le modèle qui correspond le mieux à cette organisation est la bande magnétique : il faut lire l'information depuis le début pour accéder à celle que l'on désire. Cette organisation est couramment employée sur disque bien que la structure de ce support permette d'autres accès que nous détaillerons par la suite. Quoique simple à créer (il suffit de simples ordres d'écriture) cette organisation présente de sérieux inconvénients.
-
cette méthode n'est pas efficace pour accéder rapidement à l'information puisqu'il faut lire tout ce qui précède. Dans certains systèmes la taille de l'article est indiquée en tête de celui-ci, ce qui permet d'accélérer la recherche.
-
Il est délicat de remplacer un article dans le fichier (un article correspond à la liste des variables dans un ordre d'écriture). Ceux-ci sont, le plus souvent, de longueur variable, et il ne faut pas réécrire par dessus celui qui le suit. La plupart des fonctions d'écriture ne prévoient pas cette possibilité car elles ajoutent automatiquement une marque de fin de fichier après chaque écriture. La suite est donc irrémédiablement perdue.
Accès direct
Imaginons une organisation où tous les articles auraient la même longueur. On peut alors calculer l'adresse, dans le fichier donc sur le disque, d'un article dont on connaît le rang. Si cette longueur fixe est de m octets, l'adresse a de l'article de rang n est a = (n - 1)*m. Pour accéder directement à l'article n, il suffit alors de se déplacer de a octets depuis le début du fichier. Encore faut-il connaître n. Il faut donc gérer les emplacements (ou pointeurs) pour accéder aux informations voulues.
Notons qu'il est impératif que la longueur de tous les articles soit la même. On doit prévoir, au moment de l'écriture du programme, la longueur du plus grand et l'utiliser pour tous, ce qui peut conduire à de grands gaspillages d'espace. Il est possible de remplacer ou d'ajouter un article car aucune marque de fin de fichier n'est inscrite après une écriture. Ceci permet de faire évoluer le fichier sans avoir à le reconstruire entièrement comme dans le cas des fichiers séquentiels.
La rapidité d'accès est considérablement améliorée mais le programmeur doit gérer le calcul de l'adresse. Il doit définir un algorithme de gestion de la clef d'accès. Nous présenterons ici les plus connus, parmi l'immense variété qu'on peut imaginer.
Clef univoque
On parle de clef univoque lorsqu'on peut associer directement une information à l'adresse de l'article dans le fichier. Par exemple, une société de distribution attribuera un numéro d'abonné à chacun de ses clients. Ce nombre indiquera directement le rang de l'article où sont rangées les informations correspondant à cette personne. La clef est univoque car elle est unique pour chaque client. On dispose des procédures de base :
- lire (clef, info)
- écrire (clef, info)
- supprimer (clef)
L'article est identifié par sa clef, info est sa valeur. Pour le supprimer il suffit de mettre à blanc ou à une valeur prédéfinie son contenu.
A partir de celles-ci on peut créer les procédures suivantes :
modifier(clef, info)
qui est équivalente à l'enchaînement :
lire(clef, info);
modifier_en_mémoire(info);
écrire(clef, info);
ajouter(clef, info).
Cette procédure gère la validité de la clef avant d'écrire info à sa place, c'est à dire qu'elle vérifie qu'il n'existe pas d'information déjà enregistrée à l'adresse correspondant à clef. Elle équivaut à :
lire(clef, info);
if (info==NULL) {
écrire(clef, info);
} else
{ message_d'erreur();
}
Toute la difficulté est dans la gestion univoque de la clef. Elle est simple lorsqu'il s'agit d'un numéro d'abonné mais ceci n'est pas suffisant dans la plupart des cas. Des méthodes plus sophistiquées incluent un algorithme de gestion de celle-ci.
Clef de hachage
Le principe de l'accès à clef de hachage est d'ajouter un procédé aléatoire pour calculer la valeur de la clef soit en fournissant une chaîne de caractères soit à partir d'une partie de l'information contenue dans l'article . Cette information est appelée clef primaire. Si la fonction aléatoire est de bonne qualité, les valeurs obtenues pour la clef, sont bien dispersées d'où le nom d'adressage dispersé ou de hash-coding. Dans le cas d'un fichier contenant des informations sur des personnes la clef pourrait être le champ qui, dans l'article, contient le nom et le prénom. Une fonction aléatoire f(clef_primaire) calcule la valeur a de la clef.
Le choix de la fonction f(clef_primaire) présente plusieurs difficultés. La première est que le calcul doit être rapide. Les valeurs a doivent correspondre à un intervalle numérique raisonnable car elles constituent toute l'étendue possible du fichier. Considérons, par exemple, une clef primaire qui serait un nom de personne écrit sur 30 caractères au maximum. En ne distinguant pas les majuscules des minuscules et en ignorant les autres symboles éventuellement inclus dans les noms, on se limite à 26 valeurs possibles pour chaque caractère. Il y a donc à priori 2630 combinaisons possibles. On ne peut pas réserver la place pour un fichier de 2.1042 articles! La fonction de recherche f devra donc réduire cet intervalle à une valeur raisonnable tout en évitant au maximum les cas où des clefs primaires différents aboutiraient à la même valeur a de la clef.
La fonction idéale doit posséder les propriétés suivantes :
- 0 <= f(clef) < n où n est la taille du fichier (en nombre d'articles).
- f(clef1) != f(clef2) si clef1 != clef2.
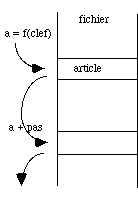
Fig. 4.10 Fichier à clef de hachage. S'il se produit une collision on se déplace de pas pour trouver une nouvelle position. |
Ces deux conditions sont évidemment impossibles à réaliser simultanément. On ne peut pas construire une fonction univoque et éviter des ambiguïtés ou collisions, c'est à dire des cas où des clefs primaires différentes généreraient la même valeur a pour la clef d'accès. Il faut gérer ce cas
Envisageons tout d'abord le cas d'une écriture. Avant d'écrire à la position a obtenue par la fonction f, on vérifiera que l'article n'est pas déjà rempli, c'est à dire que son contenu ne correspond pas à une valeur prédéterminée (on voit que le fichier doit être initialisé avant tout usage). Si tel est le cas, on recherchera la première position libre, en ajoutant à la valeur calculée a de la clef un incrément prédéfini. La valeur de cet incrément doit être première avec la taille du fichier et le calcule des nouvelles clefs doit être fait, modulo la taille du fichier, afin d'être sûr de balayer successivement toutes les positions possibles (fig. 4.10). |
L'algorithme correspond à la séquence suivante :
flag = FALSE;
/* calcul de la clef à partir de la clef primaire*/
a = f(clef_primaire);
/* recherche d'un article libre */
while (flag == FALSE) {
/* lire l'article puis extraire la valeur de la clef primaire qu'elle contient*/
lire(a, info);
extraire (clef1, info);
/* vérifier qu'elle correspond bien à la clef demandée */
if (clef1 != clef) {
/* sinon incrémenter la valeur de la clef modulo la taille du fichier */
a = (a + pas)%taille;
} else {
flag = TRUE;
}
}
Dans la réalité il est indispensable d'ajouter un critère d'arrêt à cette procédure qui peut boucler indéfiniment.
Le choix de l'algorithme f(clef) est évidemment crucial. Cependant il est étonnant de constater l'efficacité de procédures relativement simples. En considérant une clef primaire constituée d'un nom rangé sur n+1 caractères et en utilisant comme fonction de hachage f :
a =  atoi(clef[i])*position modulo la taille du fichier.
atoi(clef[i])*position modulo la taille du fichier.
où atoi() est la fonction qui retourne la valeur ASCII d'un caractère clef[i].
Le taux moyen de collision par accès ne dépasse pas 1,5 pour un fichier contenant 40 000 articles et prévu pour 70 000 articles au maximum.
Fichiers indexés
Les fichiers à clef de hachage présentent l'immense inconvénient que tout tri ou ordonnancement est long et fastidieux puisqu'il faut analyser séquentiellement les articles rangés aléatoirement.
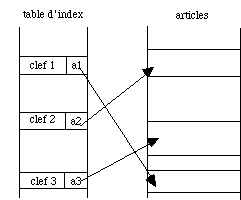
Figure 4.11 - Fichier indexé à une table d'index |
Dans un fichier indexé l'ensemble des clefs est ordonné et rangé séparément. La relation entre les clefs et les adresses des articles est établie au moyen d'une table d'index (fig. 4.11) qui peut être incluse ou séparée du fichier des articles. La manipulation des articles est aisée car elle se fait à travers de tables rapides à consulter. On peut réorganiser, trier facilement toujours au moyen de ces mêmes tables.
Il existe des algorithmes d'organisation des tables variés en fonction de l'usage prévu. On peut accélérer les recherches en organisant cette table de manière arborescente. Un fichier indexé est fragile : il suffit de détériorer la table pour perdre l'information correspondante. Pour se prémunir contre les accidents, il faut organiser une certaine redondance, par exemple prévoir dans chaque article un pointeur vers l'entrée correspondante de la table des index. Si la table est abîmée il sera possible de la reconstruire en analysant l'ensemble des informations. |
Bases de données
Les bases de données requièrent l'usage de clefs d'accès multiples. La description de leur organisation fait l'objet d'ouvrages consacrés à ce seul sujet. Nous nous proposerons seulement d'en donner un exemple.
- Imaginons une base bibliographique qui contienne pour chaque article :
les noms des auteurs
- un résumé
- les références bibliographiques (année, page et numéro de la revue)
- journal et éditeur
Les références sont uniques car un article scientifique apparaît dans un numéro précis d'une revue. Il n'en est pas de même des auteurs et de l'éditeur. Un auteur peut avoir écrit plusieurs articles, un journal contient les références de nombreux auteurs. Nous étudierons une solution à ce problème pour les auteurs uniquement.
On construit trois tables d'index séparées pour les auteurs, les éditeurs et les références. A l'intérieur de chaque article on prévoit deux pointeurs afin de créer une liste circulaire des ouvrages et des auteurs (fig. 4.12).
A partir d'une première valeur dans la table des auteurs, on retrouve rapidement un premier ouvrage de Paul, puis par les pointeurs successifs, l'ensemble de ses publications. Un deuxième pointeur permettent de parcourir cette liste en sens inverse. Seul le pointeur avant est montré dans ce dessin. Il permet de reconstruire cette structure au cas où un des pointeurs serait détérioré.
Ce choix est tout à fait critiquable : il optimise la recherche de l'ensemble des ouvrages d'un auteur, ce qui n'est pas forcément l'usage le plus utile de cette base de données. Cet exemple montre que les organisations sont très dépendantes du but recherché et qu'il n'existe pas de structure générale. Par exemple la recherche des ouvrages publiés par un éditeur ne semble pas aisée.
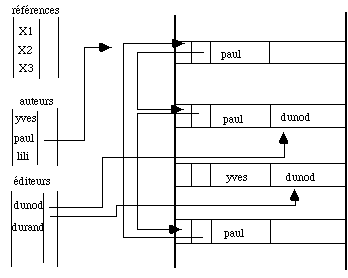
Figure 4.12 - Structure à trois tables d'index
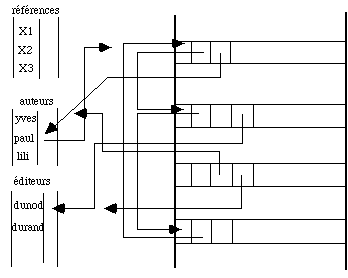
Figure 4.13 - Même base que dans la figure 4.12 optimisée pour la recherche sur critères des tables.
Cependant cette présentation est redondante: les noms d'auteurs apparaissent à la fois dans la table d'index et dans les enregistrements. Ceci augmente la taille des articles donc de la base. Ceci est également vrai pour les autres tables. On peut remédier à cela grâce à une organisation inversée où chaque enregistrement contient seulement des pointeurs sur les tables (fig. 4.13). Les noms, les éditeurs ... n'apparaissent plus en clair dans chaque article et sont remplacés par des pointeurs sur les tables correspondantes. Cette structure correspond à un usage différent du précédent. Elle permet des recherches très rapides sur les critères de définition de la base : auteurs, éditeurs, références, très lente au contraire dans l'analyse complète d'un enregistrement.
Il n'existe donc pas de structure optimale. Certaines sont plus efficaces que d'autres, indépendamment de la qualité de leur programmation, pour un usage donné mais jamais dans tous les cas.
Copyright Yves Epelboin, université P.M. Curie, février 2003, MAJ
25 février, 2007
