La compilation et l'édition des liens recouvrent toutes les opérations nécessaires pour transformer un programme écrit en langage évolué (Fortran, langage C...) en un module binaire exécutable dans la mémoire de l'ordinateur.
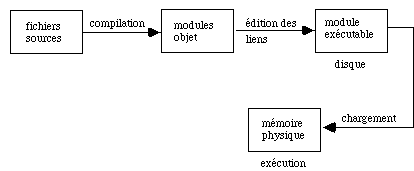
Figure 6.1 - les différentes étapes de production et d'exécution d'un programme
La compilation est la traduction en langage binaire de chaque module (fonction, sous-programme, procédure...).
L'édition des liens ajoute des modules binaires, contenus dans des bibliothèques, employés par des fonctions du programme : fonctions d'entrées-sorties, mathématiques..., ainsi que l'établissement des connexions pour enchaîner leur fonctionnement.
Ces deux étapes sont souvent effectuées l'une après l'autre, bien qu'elles correspondent à des actions très différentes et sont cachées dans une procédure commune de compilation - édition des liens. Suivant les options de la procédure on passe par l'une, l'autre ou ces deux étapes.
Le débogueur (ou debugger en anglais) est un outil de mise au point qui permet de tester le fonctionnement d'un programme. Il est possible de vérifier les valeurs de variables internes au programme sans avoir à ajouter des ordres d'écriture, de suivre pas à pas les instructions exécutées et plus généralement de controler le fonctionnement du programme. Certains débogueurs possèdent un interface graphique qui facilite leur utilisation. Nous décrirons leurs fonctions essentielles.
Les compilateurs C et C++ incluent également un préprocesseur, en fait un éditeur de texte aux possibilités réduites qui permet :
- d'inclure les lignes d'un fichier séparé #include. On peut ajouter du code source d'un fichier propre au développeur ou des compléments nécessaires à la compilation et contenus dans des bibliothèques sources de référence comme <stdio.h> par exemple.
- de définir des constantes : #define TOTO et de leur affecter éventuellement une valeur
- d'inclure ou d'ignorer conditionnellement des blocs de lignes source
- ...
La précompilation ne fait pas partie du processus de compilation. La meilleure preuve en est qu'on peut très bien l'employer dans d'autres contextes pour modifier de façon optionnelle n'importe quel fichier de texte. Ceci ne présente évidemment pas grand intérêt dans la plupart des cas mais peut s'avérer très utile, par exemple, pour du code Fortran, que l'on voudrait adapter automatiquement aux particularités de plusieurs centres de calcul. Pour employer ce précompilateur on se reportera au manuel du compilateur C dont on dispose pour lui demander de n'effectuer que cette étape de génération de code source.
Il existe également des utilitaires qui permettent de garder trace des différentes modifications d'un programme, lors de son développement. Ils sont standard dans le monde Unix. Nous n'évoquerons pas ces derniers ici.
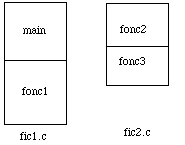
figure 6.2 : Programme source
|
On imaginera, pour illustrer ces explications, un programme rangé dans deux fichiers de nom fic1.c et fic2.c (pour les systèmes Unix l'extension .c est obligatoire pour pouvoir compiler des sources écrites en langage C). Cette extension serait .f s'il s'agissait de Fortran. Le fichier fic1.c contient (fig. 6.2) le code du programme principal appelé main ainsi que celui d'une fonction appelée fonc1. Le fichier fic2.c contient: les fonctions fonc2 et fonc3. |
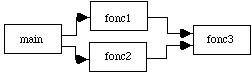
figure 6.3 : Organigramme du programme |
La figure 6.3 représente un organigramme possible: main appelle fonc1 et fonc2 successivement. fonc3 est appelée par fonc1 comme par fonc2. Cet organigramme n'est mentionné que pour illustrer le fait que le code complet d'un programme peut être rangé dans plusieurs fichiers. Il n'a aucun intérêt par lui-même. |
La compilation
Le compilateur traduit les différents modules (main, fonc1, fonc2...) en code binaire. Chaque fonction est analysée séparément sans référence aux autres. Le compilateur reconnaît les erreurs de syntaxe et peut optimiser, selon les options choisies, le code produit. Il est capable de véritables réécritures qui peuvent se traduire par des gains de temps considérables lors de l'exécution. Les résultats sont rangés dans des fichiers d'extension .o, appelés modules objets. A chaque fichier source correspond un module objet différent : fic1.o et fic2.o. Chaque module contient le codes binaire des fonctions que contenait le fichier source: main et fonc1 dans fic1.o, fonc2 et fonc3 dans fic2.o. Sauf option particulière, le compilateur n'effectue pas d'analyse interprocédurale. Chaque module est considérée comme une entité indépendante.
A ce stade on n'a pas ajouté le code des fonctions déjà compilées et rangées dans d'autres modules ou des bibliothèques, modules objets de structure spéciale, qui contiennent les codes binaires de fonctions souvent employées (entrées/sorties, mathématiques...). Le code binaire généré contient notamment des indicateurs qui marquent tous les appels à des fonctions mais ne précisent pas comment effectuer les débranchements nécessaires pour enchaîner leur exécution. Ceci est le rôle de l'éditeur de liens ou linker.
On trouve, à l'intérieur du code généré par le compilateur, pour chaque fonction, des tables qui contiennent
- les références des variables utilisées, leur type (entier, flottant...), leur qualité (scalaire, tableau...) et leur adresse interne à l'intérieur du module.
- la liste des appels à des fonctions externes à la fonction compilée.
- le code binaire généré pour chaque fonction.
Le code binaire généré par les compilateurs modernes est le même quelque soit le langage source, ce qui permet, avec certaines précautions, de créer des programmes en liant des fonctions écrites dans des langages différents. Il est courant ainsi, en calcul scientifique, de développer les interfaces en C ou C++ et les parties de calcul intensif en Fortran. Chaque module est compilé séparément puis l'ensemble est lié au moyen de l'éditeur de liens.
On se reportera au cours "Calcul intensif" pour en savoir plus sur la façon dont les compilateurs optimisent le code généré.
Edition des liens
L'utilitaire d'édition des liens analyse les informations contenues dans les modules objets et crée, à partir de ces données, le module exécutable.
Il identifie tous les appels, à des fonctions, contenus dans l'ensemble des modules objets qu'il doit lier. Il établit les débranchements nécessaires pour enchaîner leur code et recherche, dans les bibliothèques qu'on lui a indiqué, le code d'autres fonctions. Lorsqu'il les trouve il les ajoute au module exécutable qu'il construit et calcule les débranchements nécessaires à leur utilisation. Dans le schéma de la figure 6.3 il ajoute les codes binaires de fonc2 et de fonc3 à celui de main et calcule les débranchements nécessaires à leur enchaînement. L'analyse de ces fonctions l'amène à rechercher le code de fonc3 qu'il trouve dans fic2.o. Il l'ajoute également et calcule l'adresse de branchement pour exécuter cette fonction. Par définition la première instruction du programme principal possède l'adresse zéro.
Il recherche également les fonctions contenues dans les bibliothèques dont on lui a précisé l'emplacement. L'éditeur de liens explore certaines bibliothèques automatiquement, comme celles qui contiennent les fonctions d'entrées-sorties. Cependant le développeur doit indiquer explicitement le nom de certaines. Explorer systématiquement toutes les bibliothèques seraient beaucoup trop long. De plus certaines n'ont d'utilité que dans certains contextes. Imaginons, par exemple, que l'on écrive un programme qui pilote le fonctionnement d'une carte d'acquisition de données connectées au bus de l'ordinateur. Son constructeur aura fourni une bibliothèque spécialisée qui contient l'ensemble des primitives de contrôle de la carte. L'exploration de cette bibliothèque n'aura de sens que lorsqu'on écrit un module qui va utiliser celle-ci. Il conviendra donc de la mentionner dans la liste des options de l'éditeur de liens, uniquement pour les programmes qui l'emploie. Il est inutile, par contre, de préciser le nom de bibliothèques standard comme celle qui contient les ordres d'entrées-sorties ou les fonctions intrinsèques au langage employé.
Le nom du module exécutable créé est fourni par le développeur lors de l'appel à l'éditeur de liens. Le code créé par l'éditeur de liens est rangé dans un fichier qui porte ce nom. Pour exécuter le programme réalisé, il suffit de taper le nom du module exécutable. La suite des opérations a été décrite au chapitre V.
Les pièges du compilateur et de l'éditeur de liens
Lorsque le code source contient des erreurs de syntaxe le compilateur les signale. Il donne une explication en anglais et indique la ligne où il a diagnostiqué l'erreur. Il peut même, dans certains cas, tenter de les corriger. Il ne faut jamais lui faire confiance et corriger soi-même les erreurs détectées. Les diagnostics ne sont pas toujours très clairs. Ils peuvent même avoir pour origine une erreur antérieure : lorsqu'une ligne de code est erronée le compilateur l'ignore, ce qui peut causer des erreurs par la suite. Ainsi une déclaration de variable mal écrite est supprimée et est à l'origine d'un diagnostic d'erreur chaque fois que la variable est utilisée.
Une bonne règle est de corriger les premières erreurs puis de recompiler. Souvent beaucoup d'autres diagnostics vont également disparaître.
L'éditeur de liens peut également faire apparaître des erreurs. A ce stade les explications sont beaucoup moins aisées. Souvent l'éditeur de liens précise qu'il n'a pas trouvé certaines fonctions parmi les bibliothèques qu'il a exploré alors qu'on pense lui avoir fourni une liste complète.
En Fortran la cause la plus probable est une variable dimensionnée qu'on a oublié de déclarer et que le compilateur a interprété comme un fonction. Ceci est impossible en langage C où chaque fonction doit posséder un prototype.
Imaginons, en Fortran, une variable dimensionnée qui aurait du être déclarée mais a été oubliée. Par exemple :
real variable(10,20)
Il s'agit d'un tableau de 10 lignes et 20 colonnes mais si son nom n'apparaît pas à gauche d'un signe "=" le compilateur ne peut pas remarquer cette faute. Il comprend son code, chaque fois qu'il apparaît, comme le nom d'une fonction possédant deux arguments. Il crée donc le module binaire en indiquant un point d'appel à chaque usage de ce tableau. L'éditeur de liens l'enregistre dans sa table mais ne peut jamais, sauf exception, le retrouver dans aucune de ses bibliothèques. Il fournit donc un diagnostic juste en indiquant qu'il lui manque une bibliothèque! On évite cette difficulté en ajoutant à toutes les fonctions et sous-programmes l'instruction
implicit none
qui oblige à déclarer toutes les variables.
La deuxième cause d'erreur, commune au langage C et au Fortran est plus subtile. Une fonction de bibliothèque peut légitimement nécessiter un lien avec une autre fonction. Lorsque cette deuxième fonction est contenue dans une autre bibliothèque que l'éditeur de liens a déjà parcourue il ne peut pas la trouver car il explore l'ensemble des bibliothèques une seule fois, de façon séquentielle. Il indique donc un diagnostic d'erreur. L'ordre d'exploration des bibliothèques peut donc être important. Parfois il n'y a pas d'autre solution que d'indiquer deux fois le nom d'une même bibliothèque pour l'explorer à deux reprises lors de la création des liens!
La mise au point d'un programme
Lorsque le module exécutable est créé on passe à la phase de vérification. Il faut, dans la mesure du possible, employer des jeux de données particuliers qui peuvent permettre de prévoir sinon le résultat du moins son ordre de grandeur. Le programmeur doit avoir une bonne connaissance du problème traité pour savoir choisir ces jeux de données et interpréter les résultats. C'est la raison pour laquelle les chefs de projet doivent être également des spécialistes du domaine d'utilisation envisagé: un programmeur scientifique doit être un physicien, un électronicien..., un programmeur de gestion doit avoir de solides compétences dans ce domaine.
Si le programme ne fonctionne pas ou s'arrête sur un diagnostic la seule méthode de déboguage (de l'américain bug qui désigne un vilain insecte) est d'écrire des résultats intermédiaires. Le débogueur est un outil précieux pour cela. Lorsqu'un programme s'arrête sur erreur il permet de connaître l'instruction précise où l'événement s'est produit (cela demande d'utiliser des options adéquates à la compilation).
Lorsqu'on a des doutes sur la logique d'exécution il permet :
- de suivre pas à pas ou section par section le déroulement des instructions.
- de stopper l'exécution à une ligne précise
Lorsqu'on pense que certaines variables prennent des valeurs erronées il permet :
- d'imprimer leurs valeurs sans avoir à ajouter des ordres d'écriture
- de modifier la valeur d'une variable. Ceci est particulièrement utile lorsqu'on veut explorer une section d'instructions qui n'est pas normalement exploitée avec le jeu de données employé.
Il existe d'autres fonctions plus subtiles qui permettent de connaître les valeurs des registres, des piles... Un débogueur peut également permettre de vérifier que les indices des variables dimensionnées restent dans leur plage de validité.
Le principal inconvénient des débogueurs est qu'ils ralentissent considérablement l'exécution. Ceci interdit leur usage pour les programmes qui calculent longtemps, ceux qui ne peuvent être exécutés qu'en batch notamment. Dans ce cas le programmeur doit trouver ses propres méthodes pour vérifier et tester son logiciel.
Copyright Yves Epelboin, université P.M. Curie, février 2003, MAJ
25 février, 2007
