Lorsque plusieurs processus doivent accéder à un objet commun, celui-ci constitue une ressource critique. Ces processus sont alors en exclusion mutuelle pour cette ressource car ils veulent en prendre l'usage de façon exclusive. L'exemple le plus évident est celui du processeur mais cela se produit dans bien d'autres cas, par exemple lors d'entrées-sorties pour accéder à un périphérique. Deux processus qui coopérent peuvent également se trouver en exclusion mutuelle pour une ressource interne commune : imaginons, par exemple, un mécanisme de transfert où un premier processus écrit dans un tampon qu'un deuxième lit. Les deux processus doivent y accéder de façon coordonnée chacun à son tour alternativement : cette ressource est donc critique. Les parties de code qui correspondent à l'accès au tampon sont dites des zones critiques et doivent être étudiées avec soin pour éviter tout problème. Il faut gérer cette synchronisation comme schématisé dans la figure 3.4 : dans ce schéma un premier processus P écrit dans le tampon et Q ne peut le lire qu'ensuite. Les symboles S enfermés dans un cercle indiquent les points de synchronisation nécessaires et le sens de celle-ci. P envoie un message à Q pour lui demander d'attendre pendant que lui-même remplit le tampon. Plus loin il lui envoie un deuxième message pour lui indiquer qu'il a fini et Q peut transférer son contenu. Le message envoyé de Q vers P ne devrait pas servir en principe et ne sera utilisé que lorsque nous envisagerons une synchronisatioon plus complète lorsque les deux processus répètent cette opération.
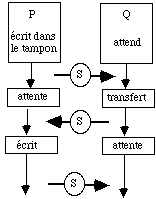
figure 3.4 : Synchronisation
La synchronisation revient à imposer des contraintes aux deux processus :
- précédence des processus : Q ne peut lire que si P a écrit.
- conditions de franchissement de certains points critiques : P ne peut écrire à nouveau que si Q a terminé le transfert.
On voit apparaître, à travers cet exemple simple, les conditions indispensables pour réaliser une synchronisation :
- les processus doivent échanger des informations. le processus synchronisable est celui qui reçoit l'information
- la synchronisation est un mécanisme bloquant : ne pourra être synchronisé qu'un processus qui attendra l'arrivée de l'information que doit lui transmettre le processus qui le synchronise.
On dit d'un processus qu'il est en attente ou bloqué s'il attend une ressource non disponible. Il faut donc définir les transitions:
- actif - bloqué pour arrêter l'exécution
- bloqué - actif pour reprendre l'exécution. On parle aussi de réveil du processus.
Les points où les processus subissent des transitions s'appellent des points de synchronisation. Nous décrirons dans la section III.2 différentes méthodes de synchronisation mais dés à présent nous pouvons en exposer la problématique au moyen d'un exemple simple.
Synchroniser deux processus se résume à l'ensemble des règles ci-dessous:
- On synchronise le processus rapide sur le processus lent. Il faut donc évaluer leur vitesse relative : si P est beaucoup plus rapide que Q, seul P doit être synchronisé. La nécessité d'une synchronisation bidirectionnelle ne se fera ressentir que dans le cas où on ne peut estimer ces vitesses relatives.
- Le processus synchronisé reçoit un signal, le processus synchronisant émet ce signal.
- Un processus n'est synchronisable qu'en un point où il est interruptible.
Reprenons maintenant l'exemple de la figure 3.4 et traduisons l'enchaînement des opérations dans un pseudo-langage proche du langage C. Nous introduisons des variables d'état e et f qui valent :
- 0 si l'événement a eu lieu
- 1 dans le cas contraire.
Les codes des processus P et Q sont :
|
processus P |
processus Q |
| e = 1; |
f = 0; |
| if ( f == 1) { |
{ if ( e== 1) { |
| attendre; } |
attendre; } |
| while (éléments à calculer) |
f = 1; |
| { calculs des éléments à transférer |
lire tampon (a); |
| écrire tampon (a); |
f = 0; |
| e = 0; } |
|
Dans ce code très simplifié les variables e et f permettent de synchroniser les processus et d'éviter que P ne réécrive dans le tampon avant que Q n'ait terminé le transfert. De même Q se met en attente si le tampon n'est pas encore rempli. On ne fait aucune hypothèse sur les vitesses relatives des deux processus. On est cependant loin d'un code complet. Rien n'est dit sur la fonction attendre, sur la façon de tester s'il y a des calculs à effectuer ou des éléments à transférer. Rien non plus sur la manière dont les deux processus P et Q peuvent partager les variables e et f ni sur le moment où ils ont démarré.
Imaginons maintenant le cas de trois processus P, Q, R qui concourent au même travail. P doit attendre que R ait fait sa part pour continuer, Q doit faire de même vis à vis de P et R vis à vis de Q. On utilise trois variables d'état e, f et g. Cela donne les éléments de code suivants :
| processus P |
processus Q |
processus R |
| e = 1; |
f = 1; |
g = 1; |
if ( g ==1)
{ attendre; } |
if (e ==1)
{ attendre; } |
f ( f== 1)
{attendre; } |
| travail à effectuer; |
travail à effectuer; |
travail à effectuer; |
| e = 0; |
f = 0; |
g = 0; |
Les trois processus vont se mettre en attente les uns sur les autres. On parle alors de verrou mortel ou dead lock (fig. 3.5).
|
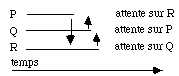
|
Cet exemple est caricatural parce que particulièrement simple à détecter. Mais lorsqu'il existe un grand nombre de processus asynchrones qui peuvent entrer à tout instant en compétition pour une ressource, le problème peut demeurer invisible tant que la machine n'est pas trop sollicitée. |
|
figure3.5 : Exemple de verrou mortel |
|
Il n'est jamais possible de prévoir le moment exact où un événement se produit car on ne connaît que les temps logiques, c'est à dire l'ordonnancement des instructions à l'intérieur des processus pris chacun séparément. On ne peut pas être certain qu'une instruction d'un premier processus se déroulera toujours avant une instruction repérée dans un deuxième si on n'a pas prévu de mécanismes d'échanges suffisants pour les synchroniser. L'ordonnancement peut se trouver modifié en cas de forte charge du système lorsque de nouveaux processus sont activés ou sollicités. Le noyau du système qui doit tenir compte de leur demande les introduit dans la liste de ceux qui dovent accéder au processeur et cela retarde forcément les processus déjà en activité. Leur ordonnancement est donc modifié et ceci peut déclencher un blocage. Ceci est bien connu des concepteurs de systèmes qui savent que des arrêts et des erreurs peuvent se produire lors des premières utilisations en vraie grandeur des systèmes qu'ils développent. C'est une des nombreuses raisons pour lesquelles il faut toujours prévoir des périodes d'essai et de montée en charge progressive. Un autre exemple de dysfonctionnement sera évoqué dans la section 3.2 : il illustre un cas où le système ne se bloque jamais mais en fonction du taux d'utilisation de la machine et de la vitesse relative des processus les résultats sont justes ou faux !
Précisons maintenant la notion de temps logique.
L'exécution du processus P peut être décrite comme la succession des instructions de son programme. Les notions de précédence et de successeur sont donc parfaitement définies à l'intérieur de P. Néanmoins celui-ci peut être interrompu en chaque point interruptible, c'est à dire entre chaque instruction. Les notions de précédence et de successeur perdent donc leur signification au niveau du système d'exploitation qui gère plusieurs processus asynchrones. L'ordre exact des instructions de l'ensemble des processus ne peut pas être prévu à l'avance. La connaissance des temps logiques des processus ne permet pas de construire de chronogramme, c'est à dire le diagramme, en fonction du temps, de la suite des instructions exécutées successivement par le processeur. L'activation des points de synchronisation se produit de manière aléatoire.
Au contraire l orsque des processus sont synchrones l'état de chacun est, à chaque instruction, parfaitement défini par rapport aux autres. Le travail coopératif est donc beaucoup plus simple à organiser.
Copyright Yves Epelboin, université P.M. Curie, 2000, MAJ
4 avril, 2005
