Rappelons tout d'abord qu'un processus est un programme en cours d'exécution dans la mémoire. Il est décrit par son contexte.
Deux processus peuvent posséder des éléments de leurs contextes disjoints ou communs. Par exemple, ils peuvent employer le même segment de code. C'est le cas dans une machine multi-utilisateurs lorsque plusieurs personnes utilisent simultanément un éditeur de texte. Une seule copie du segment programme réside en mémoire, chaque processus possède sa propre version du segment de données et son propre contexte. Il est inutile de dupliquer le segment code puisqu'il est le même pour les deux processus. Par contre leurs segments de données sont séparés parce que deux utilisateurs ne manipulent pas le même texte ni les mêmes commandes du traitement de texte. Le point où ils en sont dans l'exécution de ce code commun (entre autre la valeur du compteur ordinal) fait partie de leur environnement particulier à chacun. Un thread, par contre, possède un segment de données commun, ce qui facilite, comme nous l'avons expliqué, les échanges d'informations.
Une machine monoprocesseur simple (nous évoquerons un peu plus loin le problème des machines parallèles) ne peut effectuer qu'un seul calcul à la fois donc ne peut travailler, à un instant donné, que pour un seul processus. La simultanéité vraie n'existe donc pas. Cela signifie que pour donner l'impression de simultanéité le processeur doit s'intéresser tour à tour à chaque processus très rapidement. S'il revient suffisamment vite à chaque processus, un observateur aura le sentiment que tous les processus avancent simultanément. Seul un ordinateur qui possèderait plusieurs processeurs (machines multi-processeurs et machines massivement parallèles) permet une simultanéité complète. Cependant, nous verrons qu'on peut en donner l'apparence, avec un monoprocesseur, car l' écoulement du temps, à l'échelle d'un être humain, est infiniment lente par rapport à la rapidité d'un processeur. Comme au cinéma où la continuité du mouvement est une illusion obtenue au moyen d'un cadencement d'images fixes, le processeur peut nous donner l'apparence de la simultanéité en alternant rapidement les taches auxquelles il s'intéresse.
On peut ainsi envisager trois méthodes pour exécuter deux processus P et Q concurrents :
- Exécuter P entièrement puis charger le contexte de Q et l'exécuter à son tour (fig. 3.1). Cette méthode est simple mais frustrante pour Q qui peut éventuellement attendre longtemps! Il n'y a pas apparence de simultanéité. Nous ne nous y intéresserons donc pas.
- Alterner les deux processus: on exécute alternativement une série d'instructions de l'un puis de l'autre processus. Ils sont arrêtés en des points interruptibles ou observables. A chaque fois on sauvegarde le contexte du processus interrompu et on charge celui du processus à exécuter (fig. 3.2). Lorsqu'on abuse de ce mécanisme, le système d'exploitation peut passer un temps non négligeable dans ces opérations de changement de contexte et donc perdre son efficacité. Chaque processus s'écoule harmonieusement ; cependant lorsque le processus actif est interrompu par une entrées-sortie, il faut prévoir un mécanisme pour démarrer immédiatement l'autre processus.
- Enfin, la dernière méthode nécessite autant de processeurs que de processus (fig. 3.3). Chaque processus s'exécute sur un processeur distinct. C'est le seul cas de vrai parallélisme. Cependant si les processus P et Q concourent à la même tâche et doivent échanger des informations, on retrouvera une problématique commune aux deux autres cas car il sera nécessaire de les synchroniser. Les difficultés dans la mise au point des algorithmes parallèles tiennent essentiellement à la gestion de ces points de synchronisation et aux échanges entre processeurs. Ce problème est très étudié actuellement pour les machines massivement parallèles. Les compilateurs parallélisant comme HPF (Highly Parallel Fortran) n'y réussissent que très partiellement.
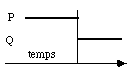
figure 3.1 : Exécution successive de P et Q
|
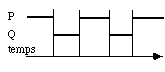
figure 3.2 : Exécution alternée de P et Q
|
|
|
Il est important de bien définir le niveau d'observation du parallélisme. Si celui-ci est le temps d'exécution total des processus, c'est à dire si le temps entre chaque observation est supérieur à la durée de vie moyenne d'un processus, alors dans tous les cas, y compris celui qui correspond au schéma de la figure 3.1, P et Q devront être considérés comme parallèles. Il en est de même pour le temps partagé: l'impression de parallélisme ressentie par chaque usager provient du fait que le temps d'exécution alloué à chaque processus est très court par rapport aux capacités d'observation d'un opérateur humain. Le moniteur alloue à chacun des tranches de temps de l'ordre de quelques dizaines de millisecondes, bien trop faibles pour qu'un homme puisse être sensible à l'échantillonnage réalisé par l'ordinateur.
Il faut donc bien retenir que l'impression de parallèlisme des différents processus qui concourent à l'activité d'un système d'exploitation, est obtenue par un alternat cadencé à une fréquence suffisante pour qu'un observateur ne puisse pas observer la discontinuité des temps de travail de chaque processus. Lorsque le nombre de processus en activité devient trop important cette illusion peut tomber et l'utilisateur peut même avoir le sentiment que l'ordinateur se bloque.
Tout l'art des concepteurs de système est d'éviter ce problème, si, évidemment, l'utilisateur n'en demande pas trop à sa machine. Même dans ce cas un bon système devrait posséder des garde-fous qui, au minimum, avertissent l'usager qu'il a dépassé les limlites, voire même qui interdisent de surcharger l'ordinateur. Unix possède certaines possibilités dans ce domaine, Windows beaucoup moins : il suffit de lancer un programme comme Photoshop et de lui demander une opération assez complexe sur une image, pour s'en apercevoir.
Copyright Yves Epelboin, université P.M. Curie, 2000, MAJ
4 avril, 2005

