Principes généraux
Le sémaphore est un moyen de communication frustre entre processus car limité à un message binaire : on passe ou on ne passe pas. On peut imaginer des primitives plus riches qui permettent la synchronisation en échangeant simultanément des informations appelées messages. Les primitives s'apparentent à des ordres de lecture et d'écriture :
- s_read(id,message) met le processus en attente d'une lecture jusqu'à ce qu'un processus de nom id envoie un message. On l'appelle une lecture bloquante.
- s_write(id,message) envoie au processus de nom id un message. Cette fonction n'est pas bloquante. Le processus qui l'utilise continue son exécution même si le processus receveur n'a pas lu le message. Celui-ci est stocké dans un tampon. Si plusieurs messages sont envoyés successivement à ce processus, leur ordre de lecture sera l'ordre d'émission des messages.
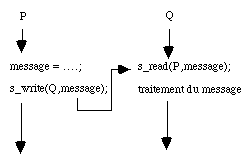 |
figure 3.7 : Synchronisation par message
|
La synchronisation par messages est très utilisée dans les systèmes d'exploitation modernes car elle permet, grâce à l'information échangée, d'envisager les traitements les plus variés. Dans la réalité il existe de nombreuses autres primitives qui permettent de réaliser des fonctions complexes. La synchronisation par message trouve aujourd'hui un usage encore plus large. Ainsi PVM et MPI sont des bibliothèques qui permettent de réaliser les fonctions d'échange, de synchronisation et de communication entre processus qui sont exécutés sur des machines en réseau. PVM et MPI sont employés sur les machines massivement parallèles.
Unix connaît un mécanisme de communication entre processus, appelé pipe, qui est un exemple de synchronisation possible par messages. Un premier processus P écrit dans le pipe, un deuxième, Q, le lit. La file d'attente correspond au modèle FIFO (fig.3.8).
Un fichier partagé est une autre méthode, très simple et efficace, pour faire communiquer et synchroniser deux processus: le premier crée et écrit dans un fichier, le deuxième en lit le contenu. On peut également utiliser l'existence ou la non-existence d'un fichier en guise de sémaphore. Ceci est souvent utilisé dans les systèmes Unix où l'on voit souvent se créer de nombreux fichiers dont l'existence est très temporaire, simplement pour permettre à un ensemble de processus de synchroniser leur activité et de communiquer l'information indispensable au bon déroulement de la fonction pour laquelle ils ont été créé. Il se peut parfois, parce qu'un processus ne fonctionne pas correctement, que ce fichier ne soit pas détruit après usage. Il suffit alors de le détruire manuellement pour retrouver un fonctionnement correct. La synchronisation par fichiers est peu performante car les opérations de lecture et d'écriture sont lentes. Elle ne peut donc pas être employée lorsqu'on a besoin de temps de réaction courts.
MPI : un exemple de synchronisation par messages
MPI (Message Passing Interface) est un projet universitaire qui a commencé en 1992. La première version officielle fut livrée au début 1994. MPI s'est imposé, depuis 1997 environ, comme le standard pour la programmation par échange de messages des machines parallèles. La bibliothèque MPI peut être employée avec C, C++ ou Fortran.
Une application est constituée d'un programme unique dupliqué sur tous les processeurs qui participent à sa réalisation. Ces différentes instances (processus) utilisent des données différentes. Leur fonctionnement est donc asynchrone et leur collaboration sera obtenue au moyen de toute une variété de fonctions d'échange de messages dont nous allons décrire les principales ci-dessous. Le modèle de programmation est SPMD (Simple Program Multiple Data).
On dispose de trois types de fonctions :
- Celles nécessaires à la connaissance de la configuration de travail : identification d'une instance, contexte de travail…
- Celles employées pour la communication entre deux processus, donc réservées à la communication point à point.
- Les fonctions destinées à la communication globale au sein d'un groupe de processus.
Parmi les arguments des fonctions ou sous-programmes on retrouve, en général, l'adresse du destinataire, le nom du tableau contenant les informations donc son adresse en mémoire (en C un pointeur), le nombre d'éléments à transférer, souvent leur type (entier, flottant…), des paramètres qui définissent l'environnement de travail du processus et toujours un code d'erreur.Le contenu d'un message MPI peut être un assemblage de types plus simples, comme le sont les structures en C. Ceci permet d'envoyer en une seule fois plusieurs variables de type différent, ce qui n'était pas possible auparavant avec PVM. On employait une technique de compactage-décompactage pour des tableaux qui contenaient des variables de type homogène. Cette opération permettait d'assurer le transcodage nécessaire lorsque les processeurs employés n'étaient pas de nature identique, comme ce peut être le cas dans un réseau de stations de travail. La méthode de compactage-décompactage a néanmoins survécu dans MPI. Les processus sont identifiés par un numéro dans un groupe. Les fonctions d'initialisation définissent quels sont les nœuds et les identifiants des processus qui participent aux divers groupes que l'on crée et initialisent ces processus et leur environnement.
Fonctions d'échange
L'environnement de travail est initialisé par :
call MPI_Init(erreur)
où erreur est un entier qui permet de savoir si l'initialisation s'est bien passée. Tous les sous-programmes MPI retournent un tel code qu'il convient de tester pour s'assurer du déroulement normal du travail. La fin du travail est déclenchée par :
call MPI_Finalize(erreur)
Le groupe auquel appartient un processus est défini dans une variable. Par défaut sa valeur est MPI_COMM_WORLD qui signifie que tous les processus appartiennent à un espace unique.
call MPI_Comm_rank(MPI_COMM_WORLD, id, erreur)
retourne l'identifiant id du processus qui emploie cet appel.
call MPI_Comm_size(MPI_COMM_WORLD, nombre, erreur)
indique le nombre de processus engagé dans ce groupe.Des appels permettent de définir un groupe, d'y ajouter ou d'en retrancher des processus de façon dynamique à tout instant.
Echanges
call MPI_Send(tableau, n, type, destination, tag, comm, erreur)
call MPI_Recv(tableau, n, type, source, tag, statut, erreur)
call MPI_Isend(tableau, n, type, destination, tag, comm, erreur)
call MPI_Irecv(tableau, n, type, source, tag, statut, erreur)
Ces appels permettent des communications plus élaborées non bloquantes. Il faut alors employer des fonctions d'attente (MPI_Wait) pour synchroniser les processus et leur faire attendre la fin d'un envoi ou d'une réception de message. Par exemple, un processus pourra donner l'ordre d'envoyer à un autre des informations et continuer à travailler. Il faudra seulement veiller à ce qu'il ne modifie pas les données rangées à l'adresse d'émission avant la fin de l'envoi. On peut ainsi exécuter du code pendant les échanges et donc paralléliser calculs et communications. L'emploi de ces fonctions est évidemment plus délicat. Un autre type d'appels permet des communications synchronisées. Une réception ne pourra commencer à s'exécuter que si l'émission correspondante a commencé. L'intérêt de ces deux derniers types d'appel est d'éviter l'emploi des tampons et donc d'améliorer la rapidité de la communication.
Il est souvent nécessaire d'envoyer des messages à tous les processus qui appartiennent à un groupe. On retrouve en particulier la possibilité de broadcast, diffusion simultanée à tous les processus et de barrière pour synchroniser tout le groupe. MPI comprend des appels plus élaborés qui ont été pensés pour la manipulation de tableaux et l'algèbre linéaire.
Exemple
Le programme ci-dessous est un exemple simple d’échange entre processus. Des commentaires sont ajoutés entre les lignes de code. Cet exemple est inspiré de « CHIMP User Guide, version 2.0 », réalisation de MPI de l’université d’Edinburgh.
Dans ce programme un processus envoie à un autre son numéro, le récepteur recommence avec le suivant et ainsi de suite pour tout le groupe.
program mpi_essai
implicit none
* header à inclure pour le fonctionnement de la bibliothèque
#include "mpi.h"
integer error, rang, taille
integer envoi, destination, suivant, i, req
integer status (MPI_STATUS_SIZE)
* Initialisation. On devrait tester le code de retour error
write(*,*) ‘Début’
*
* Initialisation
*
call MPI_Init(error)
call MPI_Set_Errormode(MPI_COMM_WORLD, MPI_ERRORSFATAL, error)
*
* retourne la référence du processus dans le groupe
* par défaut MPI_COMM_WORLD
call MPI_COMM_Rank(MPI_COMM_WORLD, rang, error)
* retourne le nombre de processus dans le groupe
call MPI_COMM_Size(MPI_COMM_WORLD, taille, error)
if (taille .lt.2) then
write(*,*) ‘Erreur, il faut au moins deux processus’
call MPI_Finalize()
stop
endif
*
* calcul des numéros des processus précédent et suivant dans le groupe
*
suivant = mod(rang + 1, taille)
tag = 0 ! paramètre nécessaire
envoi = rang
* Le processus répéte l'émission et la réception autant de fois
* qu'il y a de processus dans le groupe. Ceci juste pour
* montrer un exemple d'échanges multiples
do i = 1, taille
* Le processus de nom rang envoie son identification "rang"
* rangé dans "envoi" au processus de nom "suivant"
*
call MPI_Issend(envoi, 1, MPI_INTEGER, suivant,
& tag, MPI_COMM_WORLD, error)
*
* Le processus reçoit l’identificatif de son prédécesseur dans "recu"
* Il faut bien réaliser que les valeurs de "suivant" et "envoi"
* changent pour chaque processus du groupe
*
call MPI_Recv(recu, 1, MPI_INTEGER, precedent,
& tag, MPI_COMM_WORLD, status, error)
*
* Attente sur la fin de l’envoi avant de recommencer. Envoi bloquant.
* Autrement il y aurait risque d'écrasement des données envoyées
*
call MPI_Wait(req, status, error)
write(*,*) ‘Proc. N. ‘, rang, ‘ ‘, I, ‘--> ‘, recu
* Fin de MPI
call MPI_Finalize()
end
Copyright Yves Epelboin, université P.M. Curie 1998-2000, MAJ
30 janvier, 2006
