Définition
La notion de client serveur est fondamentale pour comprendre le fonctionnement des systèmes d’exploitation modernes. Bien qu’elle relève, en toute rigueur, d’un cours sur les communications, il est difficile de ne pas l’aborder indépendamment tant elle intervient aujourd’hui dans le fonctionnement des ordinateurs même en mode non connecté, sans aucune liaison à un réseau.
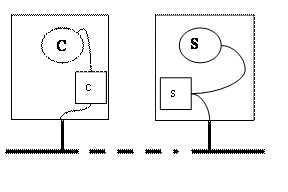
Pour comprendre le schéma du modèle client serveur on se limitera à imaginer deux processus qui s’exécutent sur une ou deux machines différentes. Ces processus peuvent communiquer entre eux au travers d’interfaces logiciels spécifiques que l’on appellera ports ou sockets. Ces interfaces sont analogues aux structures employées dans les ordres de lecture et d’écriture et mises en oeuvre par une déclaration d’ouverture de fichier fopen en langage C. La différence fondamentale est que ces deux interfaces de communication ne résident pas nécessairement sur la même machine et peuvent se trouver sur deux ordinateurs différents à des milliers de kilomètres. La façon dont la liaison est établie entre ces deux interfaces n’entre pas dans notre propos. Cela relève d’un cours sur les communications. En toute rigueur on peut imaginer un mécanisme client serveur qui fonctionnerait en employant un autre moyen de communication que les sockets. Des pipes, par exemple, pourraient convenir. La seule restriction serait alors que le client et le serveur ne pourraient résider que sur la même machine, ce qui est trop restrictif pour la généralité de ce mécanisme. Considérons deux processus S et C qui communiquent à travers des ports s et c. Ils correspondent aux deux schémas de la figure 1 suivant que les processus Set C résident sur la même machine ou sur deux machines différentes.
Considérons deux processus S et C qui communiquent à travers des ports s et c. Ils correspondent aux deux schémas de la figure 1 suivant que les processus Set C résident sur la même machine ou sur deux machines différentes.

(a) (b)
Figure 1 : deux schémas possibles pour le fonctionnement de deux processus C et S en mode client serveur :
(a) les deux processus résident dans le même ordinateur. La connexion entre les ports c et s est interne.
(b) Les deux processus résident sur des machines différentes : la connexion entre les ports se fait à travers le réseau.
Le modèle client serveur correspond à un mode de fonctionnement coopératif entre deux processus. Il est dissymétrique : le processus client C envoie une requête, sous la forme d’un message, au processus serveur S. Celui-ci la traite, c'est-à-dire qu’il effectue un certain nombre d’opérations programmées dans son code, et, au terme de ce traitement il renvoie un message en réponse au client. L’analogie la plus simple est celle d’un barman S, derrière un bar, par exemple, qui attend les clients. Lorsque C se présente et lui demande une boisson (non alcoolisée bien sûr !) S remplit un verre, selon les désirs de C, puis le lui donne.
Cette image permet de constater plusieurs traits spécifiques à ce mode de fonctionnement :
- Les rôles du serveur et du client sont dissymétriques :
le client ne sait adresser que des requêtes et attendre la réponse du serveur (être servi). Le serveur attend la demande d’un client et le sert. Pour revenir au schéma informatique de la figure 1, on voit que pour permettre à deux machines distantes de communiquer de façon symétrique selon ce principe, il faut installer un serveur et un client sur chacune.
- Ce mécanisme est un mécanisme sans état :
lorsqu’il a satisfait la requête d’un client le serveur oublie sa demande. Ceci pose un problème lorsqu’on veut dérouler un automate. Le serveur n’ayant aucun souvenir des requêtes antérieures du client celui-ci doit à chaque fois, lorsque la demande ne peut pas être satisfaite en une seule fois, lui fournir les informations nécessaires à l’exécution de la suite du processus. C’est le cas, par exemple, lorsque le processus client est une interface d’interrogation de base de données : une requête se construit habituellement par des demandes successives de plus en plus précises à la base. Il est nécessaire, à chaque stade de la recherche, de connaître les résultats de la requête précédente. Dans le modèle client serveur il est impératif que le client gère seul cet état et transmette à chaque fois au serveur le point où il en est resté. Par exemple, dans la liste d’interrogations suivante il appartient au client de préciser à chaque fois le résultat antérieur :
- rechercher les élèves de ELI2
- retenir les élèves de sexe féminin de la section ELI2
- retenir les élèves de sexe féminin de la section ELI2 dont les cheveux sont bruns
- …
Le processus client devra à chaque fois rappeler au serveur l’état antérieur. On atteint très vite des limites dans la complexité des messages échangés et des solutions diverses ont été introduites pour résoudre ce problème. Elles seront abordées dans le cours de réseaux et communications. Mais, dans son concept originel, le modèle client serveur est un mécanisme sans états.
Que doit faire le client si le serveur ne lui répond pas : panne de réseau, processus S hors d’usage, serveur saturé incapable de satisfaire la requête dans un délai raisonnable... ? Une réponse du serveur qui refuserait de traiter la demande serait une réponse légitime que devrait être gérée par le client et échappe donc à cette question. A priori le client se met en attente indéfiniment. Pour éviter un blocage il suffit que le client, s’il ne reçoit pas une réponse après un laps de temps déterminé par avance, décrète que le serveur est hors d’usage et incapable de lui répondre. Cela est équivalent à un refus qui doit être légitimement traité par le client. Ce chronomètre ou watchdog est partie conceptuelle du mécanisme client serveur.
Le modèle client serveur a été introduit dans Unix bien avant que les réseaux ne se généralisent. Il est employé abondamment pour le fonctionnement coopératif de processus dans une seule machine.
Sun, dans les années 1985 bien avant la généralisation des réseaux, justifiait le choix de ce fonctionnement d’Unix par le fait que ce mécanisme sans état permet d’éviter l’inter blocage de processus. Armés de chronomètre les processus clients peuvent éviter les situations d’attente. Intrinsèque à Unix qui fonctionne par création de processus et où leur synchronisation est un point des plus critiques, le mécanisme client serveur s’est popularisé avec la banalisation des réseaux. Il permet des échanges très souples entre processus répartis et il est possible, avec très peu d’efforts, de passer d’un mode de fonctionnement sur une seule machine à un système distribué. Lorsque les codes du client et du serveur sont bien écrits il n’y a pratiquement rien à changer pour les lancer sur une machine unique ou sur plusieurs machines différentes. Dans une acceptation plus moderne on en est donc venu à ignorer la machine physique en désignant sous le nom de serveur un ensemble de processus et leur environnement qui fournissent un service précis : serveur de fichiers, d’authentification... Il peut donc exister plusieurs serveurs sur une même machine physique et il est impossible aujourd’hui, sauf précision, de savoir lorsqu’on parle de serveur s’il s’agit de l’application seule ou de la machine sur laquelle les processus qui la composent s’exécutent.
Exemples simples
Interface de travail
On a l’habitude sur toute machine moderne de travailler avec un système de fenêtres et une souris. Dans le monde Unix on parle d’environnement X-Window. Ce fonctionnement correspond au modèle client serveur.
Le serveur X-Window gère le système de fenêtrage : taille, couleurs, position, visibilité dessus ou dessous ou masquée... Il gère également tous les aspects graphiques et les polices de caractères, intercepte les événements émis par la souris qui permettent de positionner le curseur...
Une application cliente demandera au serveur X d’afficher des caractères dans une fenêtre, par exemple. Elle se limitera à lui fournir les informations sur la fenêtre utilisée et le message à afficher. Le serveur constituera le graphique, masquera ce qui doit l’être si tout ou partie de la fenêtre est caché...
Authentification
Le fichier /etc/passwd contient, dans chaque enregistrement, un ensemble d’informations relatives à chaque usager : son identificatif et son mot de passe encrypté, son numéro d’utilisateur (uid), son numéro de groupe (gid), son nom complet (champ GCOS), son répertoire racine (home directory) et son shell de travail par défaut. De nombreux processus doivent donc le lire, non seulement au cours de la connexion pour authentifier l’utilisateur, mais pendant sa connexion pour y retrouver l’une quelconque des informations. Ceci introduit un grave problème de sécurité car le fichier passwd doit être lisible par tous, vu la diversité des propriétaires des processus qui le consulte. Une personne mal intentionnée peut donc le recopier et au moyen de logiciels spécialisés décrypter un mot de passe pour en faire mauvais usage et se masquer sous le nom de quelqu’un d’autre. Un mécanisme client serveur permet de se prémunir contre cela.
Tout processus qui voudrait accéder à une information contenue dans le fichier passwd adresser sa requête à un processus serveur seul habilité à consulter ce fichier. Celui-ci retourne les informations concernant l’usager après avoir, bien sûr, vérifié la validité de la demande. Seuls l’administrateur et le serveur peuvent consulter le fichier passwd dans son intégralité. Il devient donc impossible à un pirate de le recopier pour trnquillement, ensuite, casser les mots de passe.
Consultation d’informations sur le Web
Un client, le navigateur (Netscape, Internet Explorer ou un autre), envoie une requête à un serveur en indiquant la référence de la page qu’il veut présenter. Le serveur retourne le contenu de la page et le navigateur n’a plus qu’à employer ces données pour les afficher. Le serveur le plus populaire est Apache. Chaque demande du client est traitée séparément.
Le principe d’un mécanisme sans état a rapidement montré ses limites lorsqu’on a voulu construire des requêtes complexes. On a d’abord introduit les cookies, séries de bits échangés entre le navigateur client et le serveur, pour permettre à ceux-ci de communiquer et d’échanger un état. Les cookies permettent de coder quelques informations, forcément limitées vu leur petite longueur. En voici un exemple introduit par l’usage de Google :
.google.com TRUE / FALSE 2147368520 PREF ID=4427e19c07810a49:TM=1008598102:LM=1008598102:S=2Mwy7Tnw36E
Les différents informations codées dans le cookie permettent à Google de connaître l’état antérieur : à chaque demande le client le renvoie, Google le modifie en fonction de la nouvelle requête et le renvoie à son tour. On atteint rapidement les limites de ce mécanisme qui est lourd à gérer et, par nature, contient une information trop limitée.
Pour pallier à cette difficulté il faut répartir la gestion des échanges entre le client et le serveur donc faire du client un véritable programme complémentaire de celui qui s’exécute sur le serveur. Cela pose la question de l’hétérogénéité des systèmes d’exploitation. Le serveur unique est écrit pour une machine donnée fonctionnant avec un système d’exploitation connu à l’avance. Par contre les clients sont nombreux, surtout lorsque les interrogations viennent du monde entier. Le même serveur doit pouvoir dialoguer avec des clients installés sur les machines les plus diverses. Le serveur, avant de commencer son travail, doit donc identifier le système d’exploitation du client et lui envoyer le bon programme client. Ceci pose de nombreux problèmes : diversité des programmes clients à maintenir, trous de sécurité possibles : comment accepter, coté client, un programme inconnu qui pourrait très bien faire tout autre chose que ce pourquoi il est en principe prévu ?
Ces difficultés furent la raison pour laquelle le langage Java a été inventé. Pour éviter d’avoir à installer des clients spécifiques, Sun imagina le concept d’une machine virtuelle sécurisée qui fonctionnerait coté client en employant un langage spécifique indépendant du système d’exploitation. A la première requête le serveur envoie au client le code Java nécessaire à son fonctionnement (une applet) ; il peut alors fonctionner avec un client adapté à son usage. Il n’est plus nécessaire, du moins en principe, de créer des clients spécifiques, puisque le langage de la machine Java cliente est le même quelque soit le système d’exploitation. La sécurité est préservée puisque la machine virtuelle ne peut pas déborder de son domaine et, en particulier accéder ni aux informations ni au fonctionnement de base du système d’exploitation.
On introduisit ensuite Java du coté du serveur : ce furent les servlets. Aujourd’hui il est commun d’introduire des relais par toute une série de serveur pour faire fonctionner une application client serveur. Ceci est schématisé dans la figure 2.

Figure 2 : le client Java travaille de façon coopérative avec le serveur. Notez la position des flèches : la machine cliente est protégée contre toute malveillance par le confinement du logiciel client dans la machine virtuelle Java.
Un peu de technique
Les communications entre serveur et client peuvent obéir aussi bien au modèle sans connexion UDP ou avec connexion TCP.
L’avantage de TCP est que les communications gèrent intrinsèquement la majorité des problèmes de connexion et de validité des données échangées. L’inconvénient est que chaque requête nécessite l’établissement d’une connexion, ce qui consomme beaucoup de ressources sur le serveur et en communications. C’est le cas, par exemple, du protocole HTTP popularisé aujourd’hui dans le Web grâce aux clients Netscape et Internet Explorer et aux serveurs Apache ou IES. L’affichage d’une page complexe qui contient du texte et des images nécessite une requête par image. Le fond de la fenêtre elle-même demande une connexion. Cette page, par exemple, demande un peu moins de dix requêtes ! D’où des lenteurs inévitables par l’encombrement que cela génère sur le réseau et les ressources mobilisées dans le serveur. Des solutions apparaissent aujourd’hui : on sait maintenir ouvertes les connexions, ce qui réduit les échanges.
Pour alléger les échanges UDP présente l’avantage de ne pas demander de connexion. Par contre attention aux problèmes que le serveur et le client devront gérer seuls en cas de mauvaise communication. UDP est employé, par exemple, par les serveurs de vidéo, pour permettre de répondre efficacement à un plus grand nombre de clients. L’information est envoyée au fur et à mesure. On parle de streaming. Si tout fonctionne la réponse est plsu rapide et il n’est pas trop grave d’avoir quelques points d’image erronés.
Pour en savoir plus on consultera le cours "Réseaux et applications ".
Copyright Yves Epelboin, université P.M. Curie, avril 2003, MAJ
27 mars, 2006
